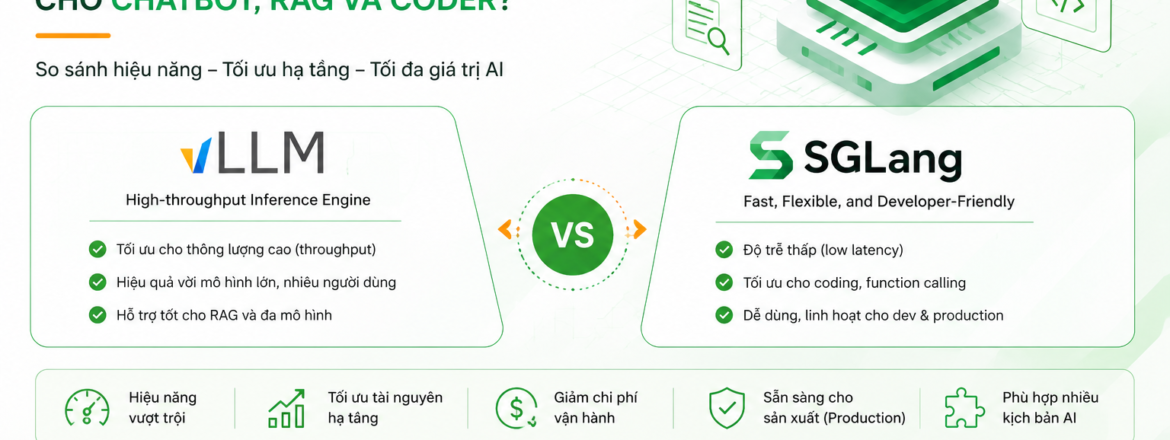
Ghép nhiều máy chủ GPU: Giải pháp chạy được mô hình có kích thước lớn hơn vRAM của GPU
Phần 1 (Lựa chọn nền tảng chạy mô hình LLM phù hợp trong môi trường on-prem: vLLM hay SGlang) chắc các bạn đọc cũng có thấy chúng tôi sử dụng một số công cụ thể ghép nhiều GPU (hoặc node có GPU) lại với nhau để xử lý các bài toán: RAG, Agentic, Coding trong […]
Read More