vLLM hay SGLang: doanh nghiệp nên chọn engine nào cho Chatbot, RAG và Coder? (Phần 2)
vLLM hay SGLang: doanh nghiệp nên chọn engine nào cho Chatbot, RAG và Coder?
2.1 Tải thấp: vLLM tạo cảm giác phản hồi rất nhanh
Ở kịch bản c1, vLLM 1N đạt 52.73 tokens/s/user và
TTFT khoảng 120ms. Đây là kết quả rất tốt cho demo vì người dùng gần như thấy hệ thống bắt đầu trả lời ngay.
| Môi trường | c1 tokens/s/user | c1 TTFT | Khách hàng cảm nhận |
|---|---|---|---|
| vLLM 1N | 52.73 | 120ms | Phản hồi nhanh nhất ở tải thấp |
| vLLM Ray 2N | 50.48 | 147ms | Rất tốt, nhưng cần Ray cluster |
| SGLang 2N | 50.04 | 178ms | Tốt, nhưng dùng nhiều node hơn |
| SGLang 1N | 33.68 | 184ms | Ổn định, thấp hơn vLLM 1N |
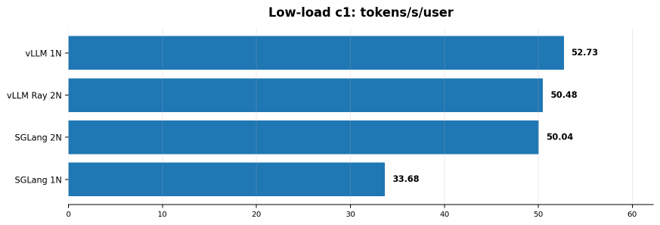
Biểu đồ 1. vLLM 1N cao hơn SGLang 1N khoảng 56.6% về tokens/s/user và TTFT thấp hơn khoảng 35%.
2.2 Tải cao: SGLang scale-out tốt hơn rõ rệt
Khi tăng lên c64, lợi thế low-load không còn đủ.
SGLang 2N đạt 298.26 tokens/s, cao hơn vLLM Ray 2N đạt 265.67 tokens/s.
Trong bộ capacity mới, SGLang 4N 1P3D đạt 480.40 tokens/s,
phù hợp cho khoảng 50–60 active chat users.
Điểm cộng của SGLang
SGLang thể hiện tốt khi dùng Kubernetes Prefill/Decode Disaggregation. Đặc biệt với Chatbot decode-heavy, cấu hình 1P3D tận dụng 3 Decode node để tăng throughput.
Điểm cần cẩn trọng với vLLM K8s
vLLM 2N K8s đạt 198.52 tokens/s và TTFT 4.78s tại c64, thấp hơn cả vLLM 1N về tổng throughput. Điều này cho thấy orchestration không phù hợp có thể làm thêm node nhưng giảm hiệu quả.
| Cấu hình | c64 total tokens/s | c64 TTFT | Nhận xét |
|---|---|---|---|
| K8s SGLang 4N 1P3D | 480.40 | 2.16s | Tốt nhất cho Chatbot tải cao |
| K8s SGLang 2N 1P1D | 298.26 | 2.59s | Mạnh trong nhóm 2N |
| vLLM Ray 2N | 265.67 | 1.43s | TTFT tốt hơn K8s |
| K8s vLLM 2N | 198.52 | 4.78s | Không khuyến nghị tải cao |
3. Coder: hai lựa chọn tốt nhất lại khác nhau
Coder là workload sinh output dài. Ở đây, SGLang 2N 1P1D và
vLLM Ray 2N đều đạt khoảng 50 tokens/s/user.
SGLang 2N đạt 50.07 tokens/s/user ở OSL2048 với latency khoảng 41.08s,
trong khi vLLM 2N K8s chỉ đạt 32.63 tokens/s/user và mất khoảng 63.05s.
| Môi trường | OSL256 | OSL512 | OSL1024 | OSL2048 | Nhận xét |
|---|---|---|---|---|---|
| SGLang 2N | 50.25 | 50.24 | 50.20 | 50.07 | Ổn định khi output dài |
| vLLM Ray 2N | 50.53 | 50.55 | 50.49 | — | Rất tốt cho Coder trên Ray |
| vLLM 2N K8s | 34.10 | 33.60 | 32.20 | 32.63 | Không nổi bật |
| SGLang 1N | 33.85 | 33.76 | 33.87 | 33.93 | Phù hợp nhóm nhỏ |
4. RAG dài: Prefill mới là câu chuyện chính
RAG dài khác Chatbot vì hệ thống phải đọc tài liệu dài trước khi trả lời.
SGLang Ray 2N đạt prefill 7,601 tokens/s và TTFT khoảng 2.16s trong bài RAG 16K ưu tiên TTFT.
SGLang 4N 2P2D phù hợp hơn nếu cần nhiều RAG 16K users, với total 42.88 tokens/s và TTFT khoảng 3.19s.
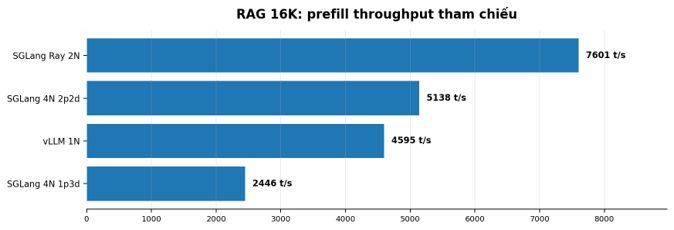
Biểu đồ 2. 1P3D rất mạnh cho Chatbot nhưng không phù hợp RAG dài vì chỉ có 1 Prefill node.
5. Bảng kết luận: nên chọn engine như thế nào?
- vLLM 1N phù hợp cho PoC/demo: triển khai đơn giản, ít overhead, TTFT thấp và tạo cảm giác phản hồi nhanh ở tải thấp.
- SGLang 4N 1P3D phù hợp cho Chatbot tải cao: tận dụng nhiều Decode worker, đạt throughput tốt nhất trong bài test c64.
- SGLang 4N 2P2D phù hợp cho Chatbot + RAG: cân bằng giữa Prefill và Decode, phù hợp hơn với workload hỗn hợp.
- SGLang 2N 1P1D hoặc vLLM Ray 2N phù hợp cho Coder: giữ tốc độ sinh output dài ổn định.
- Không có engine tốt nhất cho mọi trường hợp: lựa chọn đúng phụ thuộc vào workload chính, concurrency kỳ vọng và kiến trúc scale-out.
| Bài toán | Nên chọn | Lý do |
|---|---|---|
| PoC/demo, ít user | vLLM 1N hoặc SGLang 1N | Đơn giản, ít overhead, dễ triển khai |
| Chatbot tải cao | SGLang 4N 1P3D | Tối ưu decode-heavy, throughput cao nhất |
| Chatbot + RAG | SGLang 4N 2P2D | Cân bằng Prefill và Decode |
| RAG context dài | SGLang 4N 2P2D hoặc SGLang Ray 2N | Prefill throughput và TTFT quan trọng hơn |
| Coder / Dev Assistant | SGLang 2N 1P1D hoặc vLLM Ray 2N | Giữ tốc độ sinh output dài ổn định |
| Chưa rõ workload | SGLang 4N 2P2D | Baseline production cân bằng và ít rủi ro hơn |
Cần tư vấn triển khai LLM inference cho doanh nghiệp?
Benchmark chỉ là bước đầu để hiểu engine nào phù hợp hơn với từng workload.
Khi đi vào triển khai thực tế, doanh nghiệp còn phải tính đến mô hình sử dụng,
dung lượng GPU, số lượng người dùng đồng thời, độ dài context, kiến trúc Kubernetes,
network, monitoring, chi phí vận hành và khả năng mở rộng trong tương lai.
Nếu doanh nghiệp của bạn đang cân nhắc triển khai Chatbot nội bộ, hệ thống RAG,
Dev Assistant/Coder hoặc nền tảng LLM inference production,
CSC có thể đồng hành từ tư vấn kiến trúc, benchmark, sizing hạ tầng đến triển khai và tối ưu vận hành.
Hãy liên hệ với CSC để được tư vấn giải pháp AI infrastructure phù hợp với workload, ngân sách và mục tiêu triển khai thực tế của doanh nghiệp.

