Ghép nhiều máy chủ GPU: Giải pháp chạy được mô hình có kích thước lớn hơn vRAM của GPU
Phần 1 (Lựa chọn nền tảng chạy mô hình LLM phù hợp trong môi trường on-prem: vLLM hay SGlang) chắc các bạn đọc cũng có thấy chúng tôi sử dụng một số công cụ thể ghép nhiều GPU (hoặc node có GPU) lại với nhau để xử lý các bài toán: RAG, Agentic, Coding trong thực tế. Tuy vậy trong phần đấy chúng tôi không nói quá sâu về việc ghép nối nhiều GPU như thế nào? nền tảng công nghệ và lý thuyết nó ra sao. Trong phần 2 này chúng ta sẽ đề cập sâu hơn thông qua tìm hiểu từ Lý Thuyết đến Thực Tế để ghép nhiều GPU hay nhiều máy chủ GPU thành một system có đủ sức mạnh từ năng lực tính toán cho đến bộ nhớ để có thể: (1) Chạy được model lớn; (2) Phục vụ được nhiều user hơn.
Tại sao một GPU không đủ?
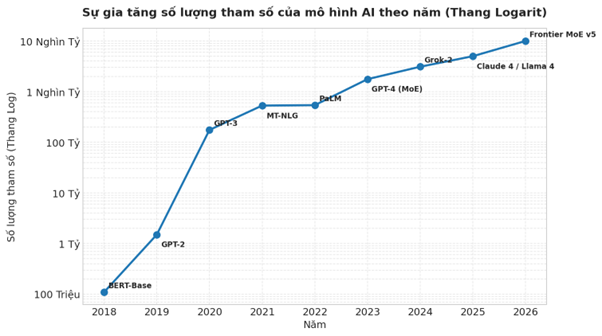
Kích thước mô hình tăng theo cấp số nhân
Năm 2018, BERT-Base của Google với 110 triệu tham số được xem là một bước ngoặt của NLP. Đó là một mô hình đủ lớn để đòi hỏi GPU để huấn luyện, nhưng vẫn đủ nhỏ để triển khai trên phần cứng thông thường.
Chỉ một năm sau, GPT-2 xuất hiện với 1.5 tỷ tham số – gấp hơn 10 lần. Một năm tiếp theo, GPT-3 nhảy lên 175 tỷ – lại gấp hơn 100 lần. Đến 2021, MT-NLG đạt hơn 500 tỷ. Nhìn lại toàn bộ giai đoạn 2018–2026 trên thang logarit, đường cong vẫn gần như tuyến tính – có nghĩa là tốc độ tăng trưởng thực tế là hàm mũ.
Từ 2023 trở đi, xu hướng chuyển mạnh sang kiến trúc Mixture-of-Experts (MoE). GPT-4, Grok-2, Claude 4, Llama 4 – các mô hình thế hệ này đều được cho là thuộc họ MoE, với tổng số tham số ước tính lên đến hàng nghìn tỷ.
Điều quan trọng hơn con số tham số là hệ quả trực tiếp lên phần cứng. Để lưu trữ và chạy một mô hình, toàn bộ trọng số (weights) phải nằm trong GPU memory (VRAM). Công thức tính VRAM tối thiểu chỉ để load model – chưa tính đến KV Cache hay activation – đơn giản như sau:
VRAM (GB) ≈ số_tham_số × bytes_per_parameter
Lấy một ví dụ có thể kiểm chứng: LLaMA 3.1 405B – một dense model với số tham số được công bố công khai – ở độ chính xác FP16 cần khoảng 810 GB VRAM chỉ để chứa model weights. Một NVIDIA B200, GPU datacenter mạnh nhất hiện tại với 180 GB HBM3e, vẫn không đủ để chạy model này một mình. Cần ít nhất 5 chiếc B200. Với H100 SXM5 (80 GB) – thế hệ đang được triển khai phổ biến nhất hiện nay – con số đó là 11 chiếc.
Quantization (kỹ thuật “nén mô hình”) làm thay đổi bài toán – nhưng không giải quyết hoàn toàn
Phản ứng tự nhiên trước bài toán memory là giảm độ chính xác của trọng số. Thay vì lưu mỗi tham số dưới dạng số thực 32-bit (FP32) hay 16-bit (FP16), có thể nén chúng xuống 8-bit (FP8, INT8) hoặc thậm chí 4-bit (INT4). Kỹ thuật này gọi là quantization, và hiệu quả của nó rất thực tế: cùng một mô hình, VRAM yêu cầu giảm tỷ lệ thuận với số bit.
Lấy LLaMA 3.1 70B làm ví dụ minh họa – một mô hình đủ phổ biến để có benchmark đáng tin cậy ở nhiều precision:
| Precision | Bytes/param | VRAM (model weights) |
| FP32 | 4 bytes | ~280 GB |
| FP16 / BF16 | 2 bytes | ~140 GB |
| FP8 | 1 byte | ~70 GB |
| INT4 | 0.5 byte | ~35 GB |
Ở FP8, LLaMA 3.1 70B lọt vừa vào một H100 SXM5 80 GB – trên lý thuyết. Trên thực tế, inference còn cần thêm bộ nhớ cho KV Cache và activation, nên con số này vẫn sát ngưỡng.
Giảm bit-width đồng nghĩa với mất thông tin. FP8 là điểm cân bằng được ngành đang dần chuẩn hoá – đủ nhỏ để tiết kiệm memory, đủ chính xác để giữ phần lớn performance.
Nhưng quantization không giải quyết hoàn toàn vấn đề. Quay lại LLaMA 3.1 405B, ngay cả với INT4, model này vẫn cần khoảng 200 GB VRAM – tương đương hơn hai H100 SXM5 (80 GB). Với các mô hình MoE thế hệ mới có tổng tham số tính theo đơn vị nghìn tỷ, không có precision nào đủ để ép toàn bộ vào một GPU đơn lẻ mà vẫn giữ được chất lượng chấp nhận được.
Không chỉ là vấn đề memory
Thực tế của production serving ngay cả khi một mô hình lý thuyết có thể fit vào một GPU sau khi quantize, một GPU đơn vẫn không đủ để phục vụ hàng trăm concurrent request với latency ở mức chấp nhận được. Memory không phải bottleneck duy nhất, throughput và concurrency cũng là giới hạn cứng.
Kết quả là: multi-GPU không còn là lựa chọn tối ưu hoá, đó là điều kiện tối thiểu để vận hành LLM ở quy mô thực tế. Câu hỏi không còn là “có cần nhiều GPU không” mà là “phân chia công việc giữa các GPU như thế nào”. Đó là bài toán của parallelism.
Các chiến lược Parallelism
Tensor Parallelism (TP)
Khi một ma trận trọng số quá lớn để nằm vừa trong VRAM của một GPU, cách tiếp cận trực tiếp nhất là cắt nó ra và phân chia cho nhiều GPU cùng xử lý. Đó là ý tưởng cốt lõi của Tensor Parallelism.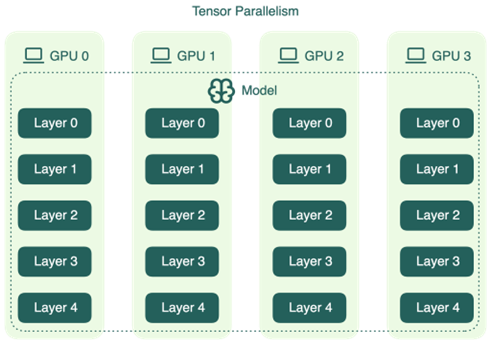
Trong một transformer layer, phần tính toán tốn kém nhất là các phép nhân ma trận lớn, đặc biệt là các projection trong attention (Q, K, V, O) và hai lớp linear trong feed-forward network (FFN). Mỗi GPU giữ một “lát cắt” của ma trận và thực hiện phép nhân trên phần của mình một cách độc lập. Đến cuối layer, kết quả từ tất cả GPU được cộng lại qua một phép all-reduce để ra output hoàn chỉnh trước khi chuyển sang layer tiếp theo.
Tuy nhiên, all-reduce sau mỗi layer là chi phí không thể tránh. Nếu bandwidth giữa các GPU không đủ lớn, overhead tích luỹ qua từng layer sẽ ăn mòn toàn bộ lợi ích của việc song song hoá.
Pipeline Parallelism (PP)
Nếu Tensor Parallelism chia một layer theo chiều ngang, Pipeline Parallelism tiếp cận theo chiều ngược lại: chia model theo chiều dọc. GPU 0 chịu trách nhiệm cho một tập layer đầu tiên, GPU 1 cho tập tiếp theo, và cứ thế cho đến GPU cuối cùng.
Ưu điểm ngay lập tức là lượng dữ liệu cần truyền giữa các GPU giảm xuống rất nhiều so với TP. Thay vì phải all-reduce sau mỗi layer, PP chỉ cần truyền một tensor activation tại ranh giới giữa hai stage liền kề. Điều đó có nghĩa là PP có thể hoạt động tốt ngay cả qua InfiniBand, tức là scale ra ngoài một node mà không bị bandwidth làm nghẽn.
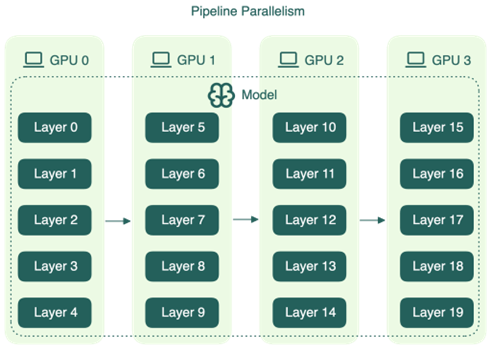
Nhưng PP có một nhược điểm mà không có cách nào loại bỏ hoàn toàn: pipeline bubble.
Hình dung theo cách này: khi một request vào hệ thống, GPU 0 bắt đầu xử lý ngay. Nhưng GPU 1 phải đợi GPU 0 xong. GPU 2 phải đợi GPU 1. Trong khoảng thời gian đó, các GPU đang chờ không làm gì cả. Đây là pipeline bubble, phần thời gian idle xuất hiện ở đầu và cuối mỗi batch vì các stage không thể bắt đầu hay kết thúc cùng lúc.
Trong training, vấn đề này được giải quyết bằng micro-batching: chia một batch lớn thành nhiều micro-batch nhỏ hơn, để khi GPU 0 chuyển micro-batch đầu tiên sang GPU 1 thì GPU 0 đã có thể bắt đầu xử lý micro-batch thứ hai ngay lập tức. Các stage chồng lên nhau, pipeline bubble co lại đáng kể.
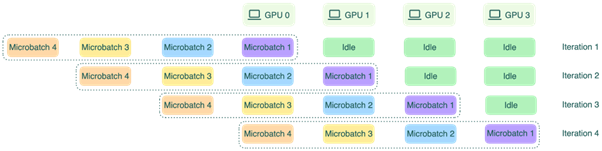
Trong inference, bài toán khó hơn. Decode phase vốn đã tuần tự theo từng token, không có micro-batch tự nhiên để chồng lên nhau. Với mô hình trải ra trên 8 hay 16 node, overhead từ pipeline bubble có thể đáng kể đến mức làm giảm hiệu quả thực tế của toàn hệ thống.
Trong thực tế production, PP hầu như luôn đi kèm với TP: TP xử lý song song hoá trong từng node, PP kéo dài chuỗi stage ra ngoài node. Hai chiến lược bù trừ cho nhau.
Data Parallelism / Tensor Replication
Trong khi TP và PP ra đời để giải quyết bài toán model quá lớn để fit vào một GPU, Data Parallelism xuất phát từ một bài toán khác hoàn toàn: model đã fit rồi, nhưng một GPU đơn không đủ để phục vụ lượng request đổ vào. Mỗi GPU hoặc mỗi nhóm GPU giữ một bản sao đầy đủ của model, xử lý một tập request độc lập hoàn toàn với các GPU còn lại.
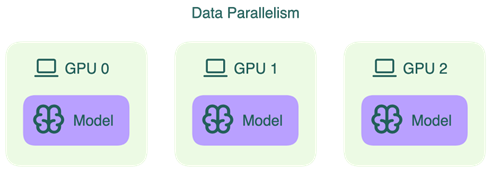
Tuy nhiên, điều kiện để Data Parallelism hoạt động là model phải fit vào VRAM của một replica. Nếu một replica là một GPU đơn, model phải fit vào GPU đó. Data Parallelism không giải quyết bài toán memory, nó chỉ nhân bản một giải pháp đã hoạt động.
Data Parallelism là lớp scale-out đơn giản nhất và hiệu quả nhất khi demand tăng, vì thêm replica về bản chất chỉ là thêm phần cứng mà không đòi hỏi thay đổi gì về cấu hình parallelism bên trong.
Expert Parallelism (EP)
Trong một mô hình Mixture-of-Experts, phần feed-forward network (FFN) của mỗi transformer layer không phải là một khối duy nhất mà là một tập hợp nhiều “expert” – về bản chất mỗi expert là một FFN độc lập.
Đây là lý do MoE hấp dẫn: tổng số tham số rất lớn, nhưng compute per token thấp vì chỉ một phần nhỏ được kích hoạt. Vấn đề là toàn bộ weights của tất cả expert vẫn phải thường trực trong VRAM, bất kể token hiện tại có dùng đến chúng hay không.
Expert Parallelism giải quyết bài toán đó. Thay vì để mỗi GPU chứa tất cả expert, EP phân bổ các expert ra nhiều GPU khác nhau. Mỗi GPU chỉ chịu trách nhiệm tính toán cho tập expert của mình.
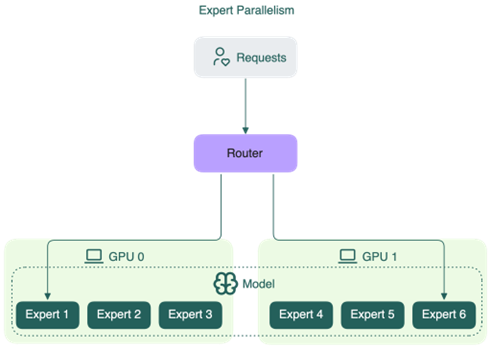
Thách thức nằm ở bước routing. Sau khi router quyết định token nào đến expert nào, các token phải được gửi đến đúng GPU đang giữ expert đó.
All-to-all khác với all-reduce của TP ở chỗ lượng dữ liệu trao đổi không cố định mà phụ thuộc vào phân phối của router. Nếu một expert được chọn nhiều hơn bình thường, GPU đó nhận nhiều token hơn và trở thành điểm nghẽn trong khi các GPU khác chờ. Hiện tượng này gọi là load imbalance, và đây là vấn đề kỹ thuật không nhỏ trong các hệ thống MoE thực tế.
Vì lý do đó, EP rất nhạy cảm với interconnect bandwidth. All-to-all xảy ra ở mỗi MoE layer, và một mô hình lớn có thể có hàng chục layer như vậy. Đây cũng là lý do EP thường được kết hợp với TP trong cùng một hệ thống: EP phân bổ expert ra nhiều GPU để giải quyết bài toán memory, còn TP xử lý song song hoá tính toán bên trong từng expert để giảm latency.
Hybrid Parallelism: TP × PP × DP
Trong thực tế, không có hệ thống production nào chỉ dùng một chiến lược parallelism duy nhất. TP, PP và DP đều có giới hạn riêng khi đứng một mình, và cách các hệ thống lớn thực sự hoạt động là kết hợp cả ba theo từng tầng, mỗi tầng giải quyết một bài toán khác nhau.
Lấy ví dụ cụ thể với 8 GPU chạy một mô hình có 10 layer, cấu hình TP=2, PP=2, DP=2 như hình.
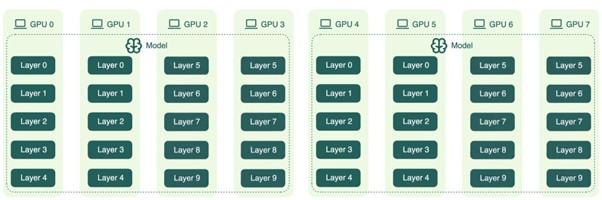
TP quyết định bao nhiêu GPU hợp lực để xử lý một layer, PP quyết định model được trải ra bao nhiêu stage, và DP quyết định toàn bộ cụm đó được nhân bản bao nhiêu lần để tăng throughput.
Trade-off giữa ba chiều này không có công thức chung. Việc tìm ra tổ hợp tối ưu phụ thuộc vào kiến trúc mô hình, topology phần cứng, và đặc tính của workload, và đây là một trong những quyết định kỹ thuật quan trọng nhất khi thiết kế một hệ thống serving ở quy mô lớn.
Thự nghiệm Tensor Parallelism trên DGX Spark GB10
Để kiểm chứng lý thuyết Parallelism, CSC Lab chúng tôi triển khai thử nghiệm thực tế trên cluster GB10 hiện có, với mục tiêu duy nhất: xác minh liệu Tensor Parallelism có thực sự giải quyết được bài toán “model lớn hơn VRAM của một node” hay không.
Model
MiniMax-M2.7-NVFP4 — kiến trúc dense, 229B tham số, định dạng NVFP4 (4-bit floating point của NVIDIA, tối ưu cho Blackwell architecture). Lý do chọn model này thay vì một dense model nhỏ hơn: kích thước đủ lớn để chắc chắn vượt quá 128GB của một node GB10 ngay cả ở precision thấp nhất hiện có, đảm bảo thử nghiệm phản ánh đúng tình huống “buộc phải dùng Parallelism”, không phải trường hợp biên.
Cấu hình chạy
2× NVIDIA DGX Spark (GB10 Grace Blackwell Superchip), mỗi node:
- 128GB unified system memory (LPDDR5x, ~273 GB/s bandwidth, chia sẻ giữa CPU/GPU)
- Kết nối liên-node qua ConnectX-7 (200GbE)
Serving qua vLLM 0.21.0, điều phối multi-node bằng Ray — 2 node ghép thành một Ray cluster duy nhất, đóng vai trò resource pool chung cho vLLM phân bổ Tensor Parallel workers.
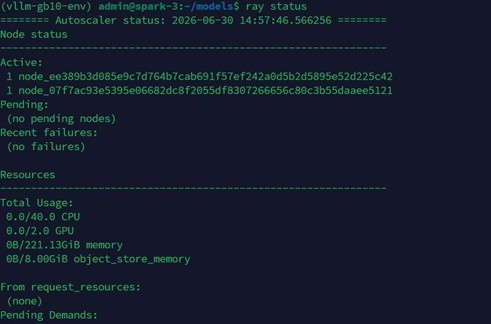
Vì sao TP=1 không khả thi
Theo nvidia-smi trên node spark-3 lúc đó, process ray::RayWorkerProc.run (PID 3300647) chiếm 91,735 MiB, tức khoảng 89.6 GB.
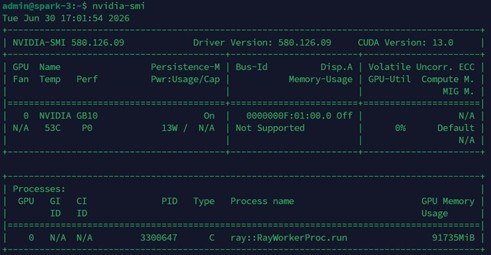
Con số này không chỉ là model weights thuần túy. Vì đang chạy TP=2, mỗi node giữ khoảng một nửa weights, cộng thêm KV Cache, activation, và CUDA context overhead phát sinh trong lúc serving. Nói cách khác, 89.6 GB là chi phí thực tế cho “một nửa workload”, và từ đó có thể suy ngược ra chi phí cho toàn bộ model nếu phải dồn vào một node: khoảng 89.6 × 2 ≈ 179 GB. Con số này vượt xa 128 GB unified memory của một node GB10.
TP=2: Load và inference thành công
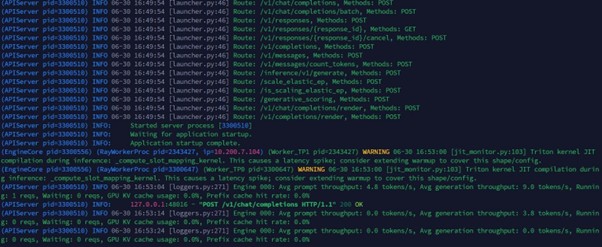
Với cấu hình TP=2 trải trên 2 node, log khởi động xác nhận server load thành công và sẵn sàng phục vụ request:
Bước cuối cùng là gửi một request thực tế và kiểm tra response:
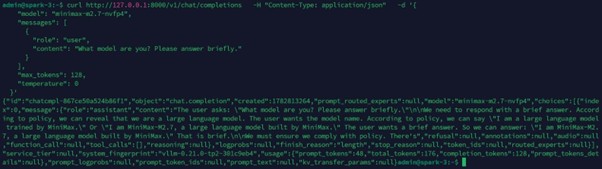
Cấu hình TP=2 trải trên 2 node không chỉ load thành công mà còn phục vụ inference đúng chức năng, được xác nhận qua cả log khởi động lẫn response thực tế từ curl.
Chúc các bạn vọc vạch thành công!

