HyperScale AI Data Platform: Khi doanh nghiệp “trò chuyện” với chính tri thức của mình
Hãy tưởng tượng bạn có một trợ lý siêu thông minh, đã đọc hết mọi tài liệu kỹ thuật, quy trình nội bộ, báo cáo và hướng dẫn sử dụng trong tổ chức. Mỗi khi bạn hỏi một câu hỏi bình thường bằng tiếng Anh hay tiếng Việt, trợ lý đó lập tức trả lời đúng trọng tâm, trích ra thông tin chính xác từ cả “rừng” tài liệu phía sau.
80% tri thức doanh nghiệp hiện nay nằm trong tài liệu, email, PDF, file đính kèm, wiki nội bộ… và gần như hoàn toàn “vô hình” với các hệ thống AI thông thường. Cloudian HyperScale AI Data Platform được thiết kế để thay đổi điều đó.
Tri thức doanh nghiệp trong tầm tay
Chúng ta đều đã quá quen với các chatbot trả lời chung chung, không hiểu gì về ngữ cảnh doanh nghiệp. Hoặc công cụ search chỉ trả về một danh sách link dài lê thê, để rồi người dùng vẫn phải tự mở từng link và đọc.
Cloudian HyperScale AI Data Platform đi theo một hướng hoàn toàn khác. Thay vì chỉ làm chatbot “hỏi đâu trả lời đó” bằng câu mẫu, hệ thống ứng dụng Agentic AI – các agent có khả năng tự ra quyết định và suy luận nhiều bước.
Khi bạn đặt một câu hỏi phức tạp về hệ thống, cấu hình, quy trình vận hành hay chính sách nội bộ, hệ thống không dừng lại ở việc tìm keyword. Nó sẽ:
- Hiểu ý nghĩa thực sự của câu hỏi
- Truy vấn trên một khối lượng lớn tài liệu, manual, hướng dẫn nội bộ
- Đánh giá tài liệu nào liên quan và đáng tin cậy hơn
- Kết hợp nhiều nguồn lại với nhau
- Tổng hợp thành một câu trả lời đầy đủ, rõ ràng, bám sát đúng mục đích bạn đang muốn thực hiện
Người dùng không cần biết tài liệu nằm ở đâu, tên file là gì, lưu trên hệ thống nào – chỉ cần hỏi theo cách tự nhiên nhất.
Bảo mật tuyệt đối, vận hành hoàn toàn on-prem
Hệ thống này chạy hoàn toàn trên Cloudian HyperScale AI Data Platform – không có bất kỳ thông tin nào rời khỏi tổ chức của bạn hay phải gửi lên cloud. Điều đó đồng nghĩa với việc toàn bộ tri thức nội bộ, tài liệu mật và dữ liệu sở hữu trí tuệ của bạn luôn được giữ an toàn, trong khi bạn vẫn tận dụng được các khả năng AI vốn trước đây chỉ có trên các dịch vụ bên ngoài.
Bài blog này mô tả chi tiết cách hệ thống hoạt động, sử dụng chính tri thức doanh nghiệp của Cloudian (trong ví dụ là một bộ tài liệu kỹ thuật khổng lồ) làm knowledge base. Điều đó cho thấy AI có thể xử lý hàng nghìn trang tài liệu phức tạp và trả lời những câu hỏi chuyên sâu về nội dung đó chỉ trong vài giây. Tri thức doanh nghiệp giờ đây có thể được truy cập tức thời – và an toàn – bởi mọi người trong tổ chức.
Bên trong HyperScale AI Data Platform
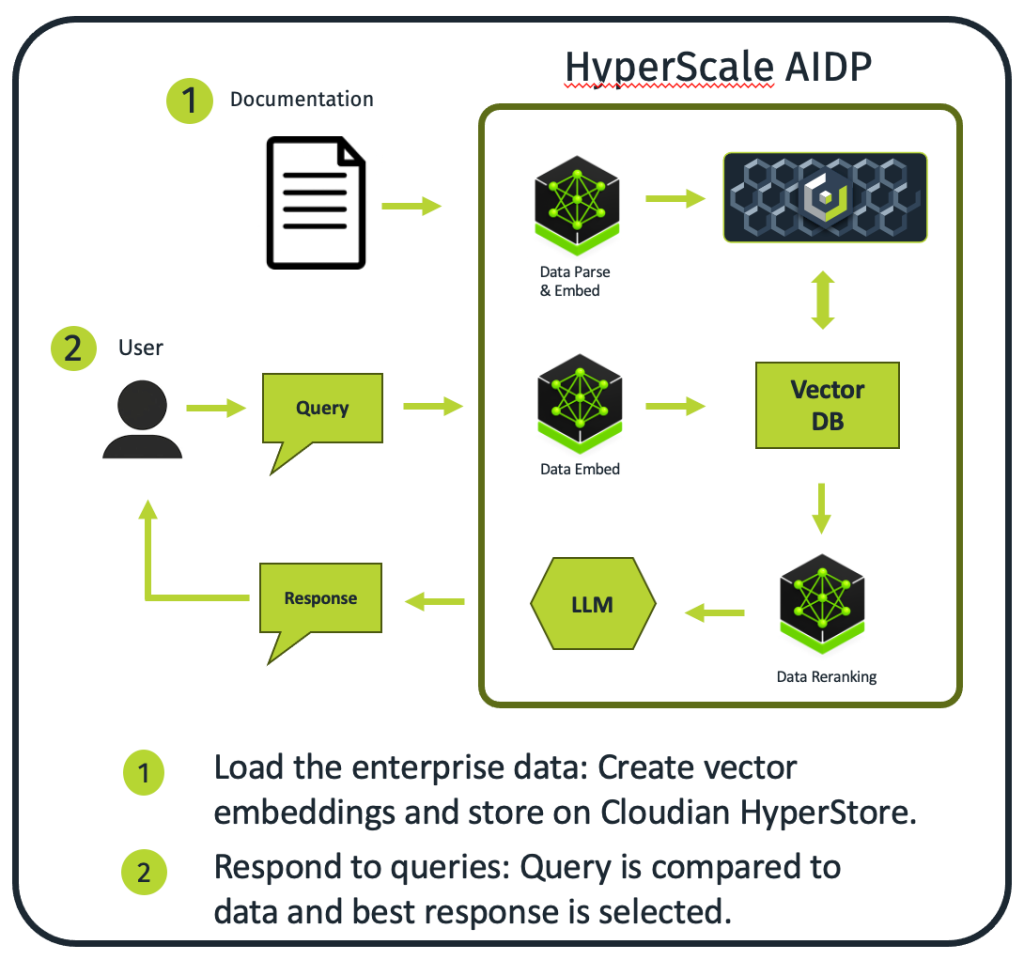
HyperScale AI Data Platform là một hệ thống AI có khả năng tự động truy xuất tri thức và tạo câu trả lời bằng ngôn ngữ tự nhiên. Giải pháp này kết hợp kiến trúc Retrieval-Augmented Generation (RAG) với hạ tầng GPU tăng tốc, tạo nên một hệ thống AI độc lập, có chủ quyền dữ liệu, có thể truy vấn và tổng hợp thông tin một cách thông minh từ các nguồn tri thức nội bộ.
Các điểm nhấn kỹ thuật chính
- Agentic AI Architecture: Kiến trúc agent cho phép hệ thống tự ra quyết định và suy luận qua nhiều bước mà không cần con người can thiệp từng bước.
- Data Sovereignty: Triển khai hoàn toàn on-prem, có thể air-gapped, đảm bảo dữ liệu của tổ chức không bao giờ rời khỏi hạ tầng nội bộ.
- GPU-Accelerated Pipeline: Toàn bộ pipeline xử lý được thiết kế để phân bổ hợp lý trên bốn GPU, tối ưu hiệu năng cho từng giai đoạn.
- Scalable Vector Search: Vector database hỗ trợ các tác vụ tìm kiếm ngữ nghĩa (semantic similarity) ở quy mô hàng tỉ vector.
- Enterprise-Ready LLM: Mô hình Llama 3.2-3B-Instruct mang lại khả năng hiểu chỉ dẫn, suy luận và đối thoại phù hợp với môi trường enterprise.
- Zero-Shot Knowledge: Không cần huấn luyện lại mô hình khi tích hợp tài liệu mới – chỉ cần nạp, xử lý và index.
Multi-Modal Support: Kiến trúc mở rộng, có thể hỗ trợ xử lý văn bản, hình ảnh và dữ liệu có cấu trúc.
Kiến trúc hệ thống
Các thành phần phần mềm AI
- AI Software Framework: Stack phần mềm sử dụng một bộ đầy đủ các thành phần phục vụ cho việc truy xuất tri thức ở cấp độ enterprise, từ parsing tài liệu, quản lý truy vấn, đến điều phối pipeline RAG.
- Vector Database: Ở “trung tâm” của các thao tác trên vector là một vector database được thiết kế cho các bài toán similarity search ở quy mô hàng tỷ vector, với độ trễ thấp và khả năng mở rộng tuyến tính.
- Language Model: Hệ thống sử dụng Llama 3.2-3B-Instruct – mô hình transformer đã được Meta tinh chỉnh (instruction-tuned), tối ưu cho hội thoại và suy luận, hỗ trợ context window lên tới 128K token, giúp xử lý được cả những chuỗi hội thoại dài và các tài liệu dung lượng lớn.
- Hạ tầng tính toán – On-prem AI infrastructure

Hạ tầng tính toán xoay quanh một node AI chuyên dụng được trang bị bốn GPU, mỗi GPU được “phân vai” rõ ràng trong toàn bộ pipeline xử lý:
- GPU 1: Xử lý inference cho Llama 3.2-3B-Instruct (LLM)
- GPU 2: Phụ trách các tác vụ của vector database và similarity search
- GPU 3: Thực hiện reranking, tính điểm mức độ liên quan (relevance scoring)
- GPU 4: Dùng chung cho việc sinh embedding và các chức năng hỗ trợ khác
Cách phân bổ workload cân bằng này giúp tối đa hóa throughput toàn hệ thống, đồng thời tránh tranh chấp tài nguyên giữa các thành phần trong pipeline, đảm bảo hệ thống vẫn ổn định và nhanh ngay cả khi số lượng truy vấn tăng cao.
Hạ tầng lưu trữ
Hệ thống sử dụng một cụm Cloudian HyperStore gồm ba node, cung cấp object storage phân tán tương thích S3 để lưu trữ vector embedding và các file index. Tầng lưu trữ này vừa đảm bảo khả năng mở rộng, vừa đảm bảo độ bền dữ liệu, đáp ứng tốt yêu cầu về quy mô rất lớn của enterprise knowledge base đồng thời vẫn duy trì được tính sẵn sàng cao cho các AI workload chạy production.
Triển khai: Knowledge Base Ingestion Pipeline
Biến dữ liệu thô của doanh nghiệp thành tri thức có thể tìm kiếm ngữ nghĩa là một trong những phần quan trọng nhất của hệ thống agentic AI. Quá trình indexing tài liệu bắt đầu khi các thành phần phần mềm AI nạp và xử lý nguồn dữ liệu – trong ví dụ này là Cloudian HyperStore Admin Guide, một bộ tài liệu quản trị hơn 1.000 trang kỹ thuật.
Luồng xử lý chính gồm các bước:
- Document Parsing: Hệ thống phân tích tài liệu, trích xuất và tổ chức lại nội dung văn bản một cách thông minh, đồng thời cố gắng giữ được quan hệ ngữ cảnh và cấu trúc phân cấp (chương, mục, tiểu mục).
- Semantic Embedding: Nội dung được chia thành các đoạn (chunk) có kích thước phù hợp rồi chuyển thành vector 768 chiều bằng các mô hình transformer hiện đại. Đây là “ngôn ngữ toán học” để hệ thống so sánh mức độ liên quan giữa truy vấn và từng đoạn nội dung.
- Index Generation: Các vector và metadata đi kèm được đưa vào vector database, xây dựng những cấu trúc index tối ưu để phục vụ tìm kiếm ngữ nghĩa với độ trễ thấp.
- Storage Persistence: Embedding và metadata được lưu bền vững trên cụm HyperStore, sẵn sàng cho các truy vấn sau này.
Về hiệu năng, toàn bộ pipeline đã xử lý xong hơn 1.000 trang tài liệu quản trị Cloudian chỉ trong khoảng năm phút. Điều này cho thấy hiệu quả của kiến trúc GPU-accelerated và cho phép doanh nghiệp liên tục onboard thêm tài liệu mới mà không làm gián đoạn hoạt động.
AI Inference Workflow
Hiểu và phân tích truy vấn
Sức mạnh của hệ thống thể hiện rõ trong cách nó xử lý truy vấn. Nhiều thành phần AI phối hợp với nhau một cách tự động để hiểu ý định người dùng mà không cần script cố định hay giám sát thủ công. Khi người dùng gửi một câu hỏi bằng ngôn ngữ tự nhiên, hệ thống lập tức bắt đầu phân tích ngữ nghĩa, sinh ra các vector biểu diễn truy vấn và so sánh toán học với các vector tài liệu đã được lưu. Đồng thời, hệ thống tự quyết định chiến lược truy vấn tối ưu, từ phạm vi tìm kiếm đến tham số và cách kết hợp kết quả.
Khả năng tự ra quyết định
Thay vì chỉ trả về những kết quả có điểm tương đồng cao nhất, hệ thống áp dụng một lớp logic ra quyết định phức tạp hơn:
- Content Evaluation: Đánh giá các đoạn tài liệu được truy xuất bằng các mô hình học máy về độ liên quan.
- Authority Weighting: Cân nhắc độ tin cậy và “độ uy tín” của nguồn tài liệu.
- Contextual Appropriateness: Phân tích xem thông tin có phù hợp với ngữ cảnh cụ thể của câu hỏi hay không.
- Dynamic Resource Allocation: Tự động điều chỉnh tài nguyên xử lý dựa trên độ phức tạp của truy vấn.
Phối hợp đa agent
Trong suốt quá trình inference, hệ thống duy trì lịch sử hội thoại và ý định người dùng qua nhiều lượt tương tác, đồng thời điều phối trơn tru nhiều thành phần AI khác nhau. Mô hình Llama 3.2-3B-Instruct tận dụng context window lớn để “ghi nhớ” các trao đổi trước đó, xử lý một lượng lớn nội dung được truy xuất và sinh ra câu trả lời đầy đủ, mạch lạc.
Các cơ chế đảm bảo chất lượng luôn vận hành song song, sử dụng ngưỡng độ tin cậy và các chiến lược fallback để đảm bảo hệ thống vẫn hoạt động đáng tin cậy ngay cả khi gặp những câu hỏi mơ hồ hoặc nằm ngoài phạm vi tri thức hiện có.
Lợi ích cho doanh nghiệp
Chủ quyền dữ liệu và bảo mật
Giải pháp đáp ứng các yêu cầu quan trọng của doanh nghiệp nhờ mô hình triển khai có thể air-gapped hoàn toàn. Tổ chức có thể vận hành hệ thống trong hạ tầng riêng, không phụ thuộc kết nối ra bên ngoài, đảm bảo các tài sản tri thức nội bộ không rời khỏi biên giới dữ liệu của doanh nghiệp. Kiến trúc này hỗ trợ tuân thủ các quy định nghiêm ngặt về vị trí lưu trữ dữ liệu (data residency) và kiểm soát truy cập, trong khi vẫn mang lại các khả năng AI tiên tiến vốn thường chỉ thấy ở dịch vụ cloud.
Khả năng mở rộng và hiệu quả vận hành
Xét về khả năng mở rộng, giải pháp thể hiện độ linh hoạt cao:
- Knowledge Base Agnostic: Có thể xử lý nhiều loại tài liệu kỹ thuật khác nhau, không bị bó buộc bởi một định dạng cụ thể.
- Incremental Updates: Cho phép cập nhật knowledge base theo kiểu incremental, gần như real-time mà không cần dừng hệ thống.
- Resource Optimization: Phân bổ GPU được thiết kế có chủ đích để tối ưu hiệu suất tính toán.
- Autonomous Operation: Hệ thống vận hành gần như tự động, giảm đáng kể nhu cầu can thiệp thủ công và chi phí vận hành.
Tối ưu chi phí
Nhờ sử dụng tài nguyên hiệu quả và mô hình vận hành tự động, hệ thống mang lại hành vi hiệu năng ổn định, dễ dự đoán. Điều này giúp doanh nghiệp lập kế hoạch trải nghiệm người dùng và năng lực phục vụ một cách chủ động, đồng thời giảm chi phí vận hành lâu dài.
Ứng dụng thực tế
Giải pháp agentic AI này có thể được áp dụng cho nhiều kịch bản trong doanh nghiệp, bao gồm:
- Technical Documentation Systems: Tự động giải đáp các câu hỏi cấu hình phức tạp và các tình huống troubleshoot, nhờ truy cập tức thời vào đúng phần tài liệu kỹ thuật liên quan.
- Customer Service Enhancement: Hỗ trợ đội ngũ chăm sóc khách hàng với khả năng truy xuất thông tin kỹ thuật chính xác, rút ngắn thời gian xử lý và cải thiện mức độ hài lòng của khách hàng.
- Research and Development: Cung cấp quyền truy cập nhanh vào tri thức nội bộ, giúp đội ngũ R&D đẩy nhanh tốc độ nghiên cứu và đổi mới bằng cách giảm thời gian tìm kiếm thông tin rời rạc.
- Compliance and Training: Tự động diễn giải chính sách và quy trình, cung cấp hướng dẫn bám sát ngữ cảnh, giúp nhân viên luôn nắm được thông tin chính xác và mới nhất.
- Knowledge Management: Tập trung hóa tri thức tổ chức, với khả năng tổng hợp thông minh, kết nối thông tin giữa nhiều lĩnh vực và giai đoạn khác nhau.
Hướng phát triển tương lai
Kiến trúc của hệ thống được thiết kế để sẵn sàng mở rộng, bao gồm khả năng xử lý đa phương thức (multi-modal) cho hình ảnh, sơ đồ, biểu đồ và dữ liệu có cấu trúc. Doanh nghiệp có thể tích hợp thêm các nguồn tri thức mới hoặc mở rộng khả năng suy luận thông qua fine-tuning hay nâng cấp từng thành phần riêng lẻ mà không cần thay đổi kiến trúc lõi.
Enterprise AI Unleashed – Biến dữ liệu phi cấu trúc thành năng lực AI với NVIDIA và Cloudian
“Các doanh nghiệp đang dần nhận ra rằng họ đang ngồi trên một mỏ vàng khổng lồ – và mỏ vàng đó chính là dữ liệu. Vấn đề là họ chưa biết cách xây dựng một pipeline tối ưu, hay cách ‘đào’ dữ liệu đó hiệu quả hơn như thế nào… Vì vậy, một giải pháp out-of-the-box như thế này thực sự rất hữu ích – và đó chính là giá trị mà [Cloudian] mang lại.”
Ashutosh Malegaonkar
Senior Director, Networking, NVIDIA
Tham khảo thêm tại đây!

