Gỡ rối: Làm thế nào để phân biệt một Lake House với một Data Lake?
Bạn có bao giờ bối rối về sự khác biệt giữa kho dữ liệu (data warehouse), hồ dữ liệu (data lake), nhà bên hồ (lake house) và lưới dữ liệu (data mesh) không? Bruno Rodrigues Lopes, kiến trúc sư giải pháp cấp cao tại Bradesco, đã đăng một số định nghĩa và sự khác biệt đáng chú ý trên LinkedIn, đưa ra một cách tốt để xem xét các cấu trúc dữ liệu khác nhau này.
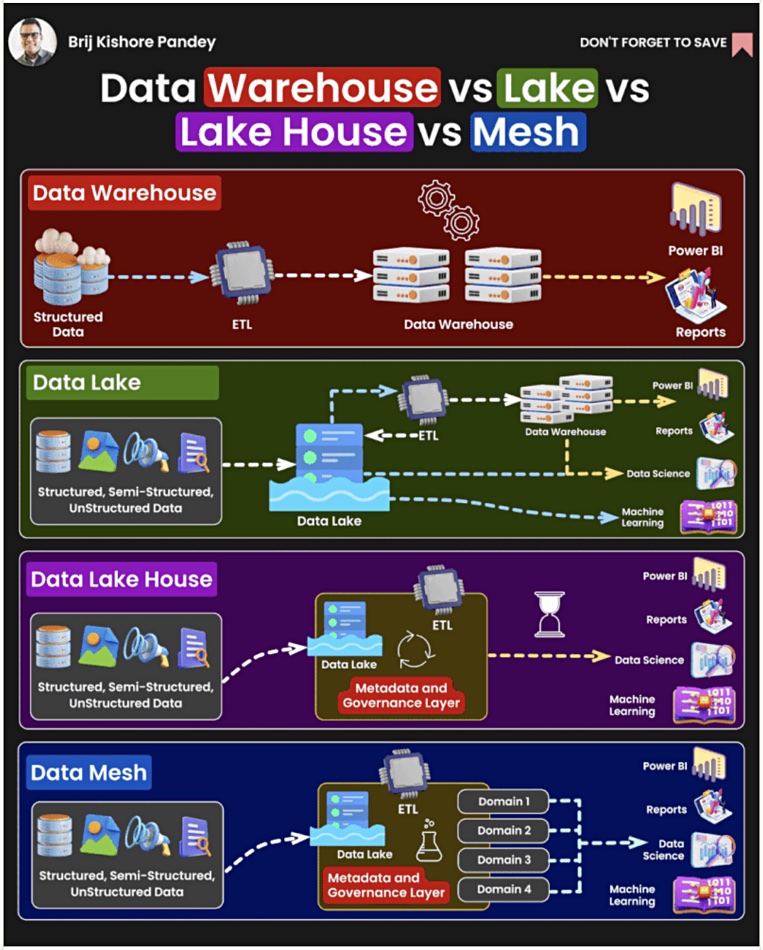
Hãy đặt điểm neo với sự khác biệt giữa cơ sở dữ liệu và kho dữ liệu. Các bản ghi dữ liệu có cấu trúc hiện hữu, theo thời gian thực được lưu trữ trong cơ sở dữ liệu. Kho dữ liệu, chẳng hạn như Teradata, được giới thiệu vào cuối những năm 1970, lưu trữ các bản ghi cũ hơn trong kho dữ liệu có cấu trúc của nó với lược đồ cố định cho việc phân tích dữ liệu lịch sử. Dữ liệu thường được tải vào kho dữ liệu thông qua quy trình Extract, Transform và Load (ETL) được áp dụng cho cơ sở dữ liệu. Ví dụ: người dùng chuyên môn trong doanh nghiệp truy vấn dữ liệu, sử dụng ngôn ngữ truy vấn có cấu trúc (SQL) và mã kho được thiết kế để xử lý truy vấn nhanh.
Sơ đồ của Brit Kishore Pandey
Hồ dữ liệu kết hợp một lượng lớn dữ liệu có cấu trúc, bán cấu trúc và không cấu trúc. Việc đọc dữ liệu thường đồng nghĩa với việc lọc dữ liệu thông qua cấu trúc được xác định tại thời điểm đọc và có thể liên quan đến quy trình ETL để đưa dữ liệu đã đọc vào kho dữ liệu. S3 hoặc kho lưu trữ đối tượng khác có thể được coi là hồ dữ liệu nơi nội dung của nó có thể được các nhà khoa học dữ liệu và học máy sử dụng.
Như chúng ta có thể mong đợi từ cái tên của nó, kho dữ liệu nhằm mục đích kết hợp các thuộc tính của kho dữ liệu và hồ dữ liệu, và nó đang được sử dụng cho cả hoạt động kinh doanh thông minh (Business Intelligence), như hồ dữ liệu và cả tải xử lý học máy. DeltaLake của Databrick là một ví dụ. Nó có các chức năng ETL nội bộ riêng, tham chiếu đến metadata nội bộ nhằm cung cấp cho thành phần kho dữ liệu của nó.
Lưới dữ liệu là một cách sử dụng kho dữ liệu và hồ dữ liệu (warehouse và lakehouse). Khi bắt đầu, hai khái niệm này thường có một nhóm dữ liệu tập trung xử lý các câu hỏi từ nhà quản lý và lãnh đạo mảng kinh doanh (Line of Business) cần các quy trình phân tích được chạy trong lakehouse hoặc warehouse, cũng như việc duy trì lakehouse/warehouse. Khi tải phân tích gia tăng, nhóm trung tâm này có thể trở thành nút thắt cổ chai, cản trở việc tạo quy trình phân tích kịp thời. Họ không hiểu các ràng buộc và ưu tiên của LOB, điều này làm tăng thêm độ trễ.
Nếu LOB, những người trong lĩnh vực cụ thể có thể viết truy vấn của riêng họ, bỏ qua nhóm trung tâm thì quy trình truy vấn của họ sẽ được viết và chạy nhanh hơn. Việc phân phối các truy vấn này cho các nhóm LOB, hoạt động trên cơ sở tự phục vụ phi tập trung, là bản chất của phương pháp lưới dữ liệu. Họ thiết kế và vận hành data pipeline của riêng mình bằng cách sử dụng warehouse và lakehouse làm nền tảng hạ tầng dữ liệu.
Cách tiếp cận lưới dữ liệu được hỗ trợ bởi các nhà cung cấp như Oracle và Snowflake, Teradata và các nhà cung cấp khác.
Vậy là chúng ta đã có nó – bốn cấu trúc container chứa dữ liệu được đóng gói, sẵn sàng được lưu giữ trong các kịch bản của bạn và được triển khai khi cần đến.
Nguồn Blocks & Files

