Lưu trữ dữ liệu cho AI: Càng lớn hơn, càng tốt hơn
Tại sao AI cần đến một ‘đại dương dữ liệu’?
Đầu năm nay, chúng tôi đã đăng một bài blog dự đoán về sự xuất hiện của đại dương dữ liệu (Data Ocean) và gợi ý rằng sự cần thiết của chúng sẽ được thúc đẩy bởi thị trường Trí tuệ Nhân tạo toàn cầu. Trường hợp dự đoán có thể bị sai lệch là khi nó ám chỉ đến việc mở rộng từ Data Lake sang Data Ocean. Mặc dù bạn có thể tạo ra một ngọn núi từ một đụn đất, nhưng bạn không thể tạo ra một đại dương từ một cái hồ. Nói cách khác, việc sử dụng cụm từ “kéo dãn hồ dữ liệu thành đại dương dữ liệu” là không chính xác về mặt ngữ nghĩa, nhưng ý tưởng phát triển hồ dữ liệu và chuyển nó thành đại dương dữ liệu sẽ ghi nhận chính xác hướng đi mà chúng ta đang thấy các doanh nghiệp dựa trên dữ liệu đang dịch chuyển.
Trước khi đi xa hơn, hãy nói một chút về những gì tạo nên đại dương dữ liệu, bắt đầu bằng định nghĩa về hồ dữ liệu. Hồ dữ liệu chứa dữ liệu thô, chưa được xử lý, theo truyền thống tập trung vào một phần cụ thể của doanh nghiệp và thường không có kỳ vọng thực sự về hiệu suất cao. Để so sánh, đại dương dữ liệu mang tính mở rộng hơn nhiều và cung cấp quy mô rất lớn để giữ lại dữ liệu giống như hồ dữ liệu, bên cạnh dữ liệu nhỏ và rộng cần thiết để cung cấp góc nhìn cho việc phân tích tốt hơn. Dữ liệu nhỏ và rộng có thể là những thuật ngữ mới đối với một số người, vì vậy, việc đưa ra bản tóm tắt nhanh có thể là điều tốt. Dữ liệu nhỏ là một kỹ thuật phân tích để khám phá những nắm bắt thú vị và có ý nghĩa từ các tập dữ liệu riêng lẻ, nhỏ hơn, trong khi dữ liệu rộng là việc liên kết các nguồn dữ liệu khác nhau trên nhiều nguồn khác nhau để đưa ra các phân tích hữu ích. Dữ liệu rộng có thể thể hiện thói quen hoặc xu hướng mua hàng của một số khách hàng nhất định đã mua các nhãn hiệu sản phẩm cụ thể, trong khi dữ liệu nhỏ có thể được coi là đối lập với dữ liệu lớn ở chỗ nó cung cấp phân tích hẹp hơn nhiều về một điểm trọng tâm duy nhất và do đó sẽ khó hơn để trích xuất từ các tập dữ liệu lớn. Một ví dụ tuyệt vời về dữ liệu nhỏ là cái được gọi là “LEGO beat-up sneaker” và đó là những quan sát rất thuyết phục về sức mạnh mà các tổ đang tìm kiếm trong dữ liệu nhỏ. Một phân tích của Gartner năm 2021 dự đoán rằng, đến năm 2025, “70% tổ chức sẽ chuyển từ tập trung vào dữ liệu lớn sang dữ liệu nhỏ và rộng”. Việc chuyển sang dữ liệu nhỏ và rộng này sẽ cung cấp cho khách hàng những bộ dữ liệu nhỏ hơn, riêng biệt hơn để có bối cảnh rộng hơn và đảm bảo trí tuệ nhân tạo (AI) có lượng dữ liệu dồi dào cần thiết để hoạt động tối ưu.
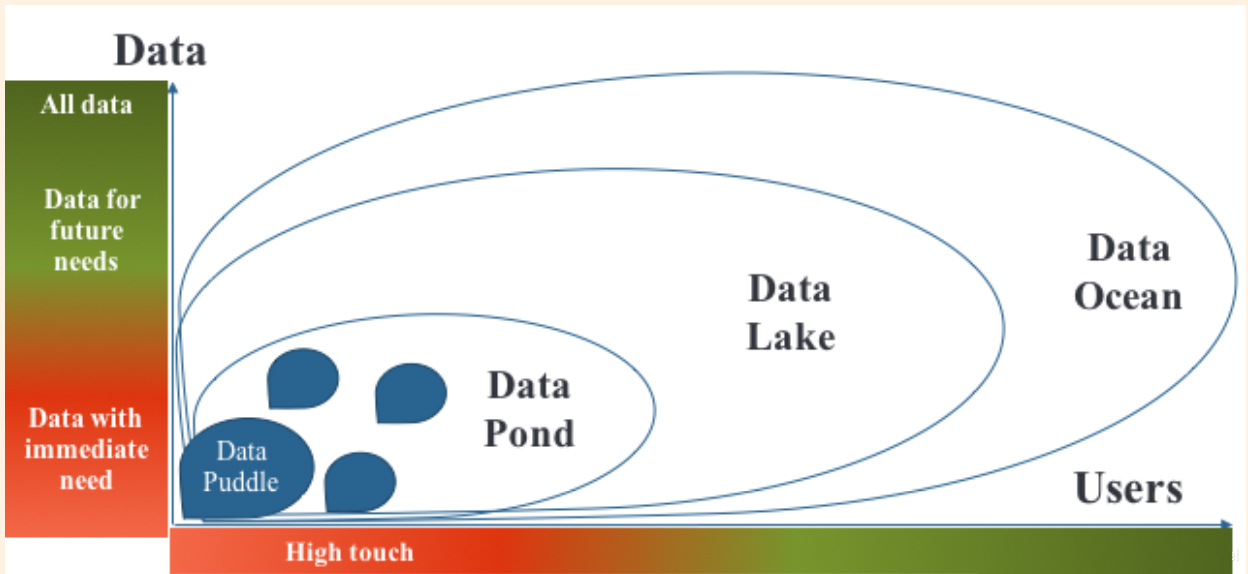
Các doanh nghiệp, cơ quan và tổ chức đã sử dụng lượng dữ liệu khổng lồ trong vài thập kỷ qua và khi lượng dữ liệu tiếp tục tăng lên, việc tìm ra những cách mới để sử dụng dữ liệu này đã trở thành một thách thức. Hồ dữ liệu, một thuật ngữ do Jim Dixon, cựu CTO và người sáng lập Pentaho đặt ra, là một cách để mô tả một kho lưu trữ nơi tất cả dữ liệu thô, chưa được xử lý sẽ được lưu trữ trong trường hợp nó có thể có giá trị tại một thời điểm nào đó. Tuy nhiên, sự tăng trưởng dữ liệu đã tạo ra một “vùng đất của các hồ dữ liệu” hay còn gọi là các “silo” và các người ta nhanh chóng phát hiện ra rằng hồ dữ liệu nếu không được theo sát có thể biến hồ dữ liệu thành một “đầm lầy dữ liệu”!
Đi sâu hơn
Chúng tôi đã đề cập ngay từ đầu rằng thị trường trí tuệ nhân tạo toàn cầu sẽ thúc đẩy sự cần thiết của đại dương dữ liệu. Hãy cùng đi sâu vào và mở rộng nhận định đó. Vào đầu những năm 90, thuật ngữ “dữ liệu lớn” lần đầu tiên được sử dụng, sau đó đến đầu những năm 2000, nó được sử dụng để giải thích hiện tượng tăng trưởng trong các giải pháp phân tích kinh doanh được thúc đẩy bởi Hadoop và tất cả các phiên bản giống với Hadoop. Mọi người đều nói về “dữ liệu lớn” và phân tích dữ liệu, nhưng như bạn chắc chắn đã nghe nói đến, mức độ liên quan của Hadoop đã giảm đáng kể do khách hàng muốn phân tích dữ liệu của họ nhanh hơn và riêng biệt hơn cũng như một nền tảng có thể thực hiện học máy và học sâu.
Bây giờ, trước khi tiến sâu hơn, hãy giải thích hai loại AI riêng biệt. Đầu tiên, đó là Trí tuệ thu hẹp nhân tạo (Artificial Narrow Intelligence), hay ANI, và Trí tuệ nhân tạo tổng hợp (Artificial General Intelligence), hay AGI. ANI là thứ thường có sẵn trên thị trường hiện nay, nghĩa là nó được thiết kế để thực hiện một tác vụ cụ thể, chẳng hạn như chơi cờ, nhận dạng giọng nói thông qua trợ lý giọng nói như Alexa, Siri và Google Home, đưa ra dự đoán dựa trên dữ liệu xu hướng, v.v. Các giải pháp hoặc hệ thống ANI này được cung cấp dữ liệu và kết quả có thể xảy ra trong mô hình đào tạo, tạo ra kết quả rất giống với kết quả phản hồi của con người với một kịch bản phản hồi định trước. Ở góc độ khác, chúng ta tiếp cận nhiều hơn các mô hình Trí tuệ tổng hợp nhân tạo (AGI) như GPT-3 và GPT-4 đã đi tiên phong trong các công cụ đàm thoại giống với con người, và các hệ thống chuyên gia y tế tiên tiến hơn bắt đầu bắt chước quá trình học hỏi của con người từ những trải nghiệm và tương tác mà nó có cũng như tạo ra với dữ liệu được thể hiện và dữ liệu mà nó tạo ra theo thời gian.
Một số người ví AGI như việc một đứa trẻ học tập và xử lý dựa trên hành động và phản ứng. Hành động có thể không được mô hình đào tạo nhắc nhở, nhưng phản ứng cung cấp thông tin chi tiết về dữ liệu và logic mà nó sẽ áp dụng trong lần lặp tiếp theo của hành động này. Mặc dù ngày nay các nền tảng AGI được nhận thức đầy đủ không tồn tại nhưng AGI là một lĩnh vực có sự tăng trưởng mạnh mẽ trong tương lai. Để sự tăng trưởng đó diễn ra, nó không chỉ đòi hỏi một kho lưu trữ sâu rộng và mở rộng như đại dương dữ liệu mà còn cần một nền tảng để dữ liệu đó có thể được phân phối và xử lý. Cần có hai thành phần quan trọng để hỗ trợ loại sáng kiến AGI lớn này: hiệu suất lớn và kho lưu trữ có năng lực cấp độ exascale.
Tốc độ và hiệu suất của cơ sở hạ tầng dữ liệu sẵn sàng cho AGI sẽ rất quan trọng – không chỉ hiệu suất đọc mà còn hiệu suất ghi. Với ví dụ trước đó về xử lý dữ liệu con dựa trên hành động và phản ứng, đâu đó còn tồn tại một nhu cầu thực sự không chỉ là đọc dữ liệu vào, như hầu hết các giải pháp ANI đều làm mà còn xuất dữ liệu ở tốc độ cực cao để cho phép giải pháp AGI xây dựng lặp đi lặp lại quá trình học tập và trải nghiệm bên trên nó. Hãy suy nghĩ về những hạn chế bạn sẽ gặp phải nếu giải pháp của bạn chỉ có thể ghi ở tốc độ 5, 10 hoặc 20GB/giây. Điều đó không chỉ làm chậm quá trình học tập mà còn khiến hạ tầng dữ liệu rất đắt tiền được cung cấp bởi GPU của bạn về cơ bản sẽ không hoạt động.
Thị trường trí tuệ nhân tạo toàn cầu dự kiến sẽ cho thấy sự tăng trưởng rất mạnh mẽ trong 5 – 10 năm tới với quy mô thị trường dự kiến là gần 2 nghìn tỷ USD vào năm 2030, có lẽ sẽ đưa ngành công nghiệp của chúng ta ngày càng đến gần hơn với Trí tuệ nhân tạo tổng hợp (AGI) thực sự. Chúng ta có thể đi trước làn sóng bằng cách triển khai đại dương dữ liệu như một phần của hạ tầng dữ liệu của mình, điều đó sẽ là chìa khóa thành công của nhiều tổ chức đã đặt AI/ML làm sáng kiến hàng đầu trong lộ trình của họ.
Kết luận
Trong kỷ nguyên dữ liệu lớn, việc đưa ra quyết định sáng suốt đòi hỏi một chiến lược quản lý dữ liệu mạnh mẽ. Mặc dù các hồ dữ liệu đóng vai trò là công cụ có giá trị để lưu trữ khối lượng lớn dữ liệu, nhưng khái niệm về đại dương dữ liệu sẽ đưa việc quản lý dữ liệu và trí thông minh dữ liệu lên một cấp độ mới. Bằng cách kết hợp khả năng mở rộng cấp exascale với độ trễ cực thấp, khả năng truy cập dữ liệu hiệu suất cao cũng như khả năng truy cập dữ liệu rộng và được cải thiện, đại dương dữ liệu, hay Data Ocean, cung cấp giải pháp toàn diện và hiệu quả hơn để điều hướng các biển dữ liệu rộng lớn. Áp dụng cách tiếp cận đại dương dữ liệu cho phép các tổ chức khai thác toàn bộ tiềm năng của tài sản dữ liệu của họ và tự tin hướng tới thành công trong thế giới dựa trên dữ liệu.
Nguồn WEKA Blog

