vLLM vs SGLang: Nên Chọn Engine AI Nào?
vLLM hay SGLang: doanh nghiệp nên chọn engine nào cho Chatbot, RAG và Coder?
Câu hỏi thường gặp: “vLLM hay SGLang tốt hơn?”
Câu trả lời đúng không phải là chọn một engine cho mọi tình huống.
Benchmark cho thấy vLLM rất mạnh ở tải thấp/single-node,
trong khi SGLang nổi bật hơn khi scale-out
cho Chatbot tải cao, RAG dài và workload hỗn hợp.
Ở bài viết này, chúng ta sử dụng một cụm AI với cấu hình như sau:
- 4 DGX Spark, mỗi node sử dụng unified GPU memory 128GB VRAM
- 1 Switch MikroTik với bandwidth 200Gbps
- Cụm Kubernetes với 4 worker node
- Mô hình LLM thử nghiệm: Qwen3.6-35B-A3B-FP8
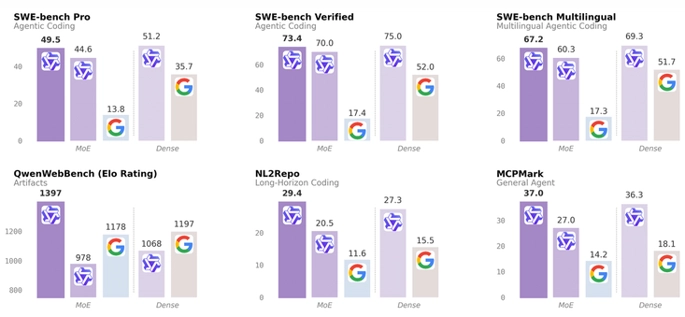
Benchmark mô hình Qwen3.6-35B-A3B-FP8
Mô hình triển khai thử nghiệm
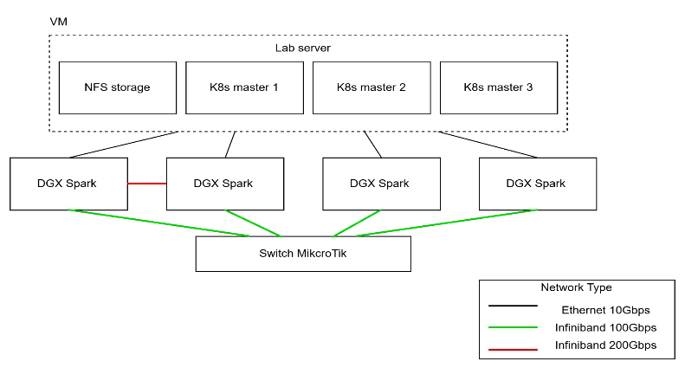
Hình 1. Sơ đồ thiết kế kiểm thử với DGX Spark
Mô hình inference tham khảo
Chúng ta có thể tham khảo mô hình inference sau:
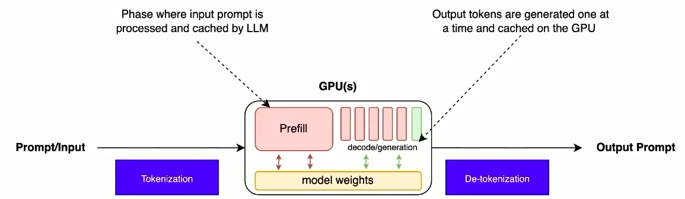
Hình 2. LLM inference pipeline
Chú thích thuật ngữ
- xN: số node DGX Spark sử dụng trong bài test, từ 1 đến 4 node.
- P – Prefill: giai đoạn mô hình nhận input và xử lý prompt.
- D – Decode: giai đoạn mô hình sinh token để trả về kết quả.
- 1P2D: 1 worker làm Prefill, 2 worker làm Decode.
1. Kịch bản thử nghiệm
Để trả lời câu hỏi “vLLM hay SGLang tốt hơn?”, chúng ta không thể chỉ nhìn vào một benchmark đơn lẻ.
Trong thực tế triển khai cho doanh nghiệp, cùng một mô hình LLM nhưng workload khác nhau sẽ tạo ra bottleneck khác nhau.
Một chatbot thông thường cần phản hồi nhanh và duy trì trải nghiệm mượt khi nhiều người dùng cùng truy cập.
Một hệ thống RAG lại phải xử lý input dài, đọc nhiều tài liệu trước khi sinh câu trả lời.
Trong khi đó, Coder hoặc Dev Assistant thường phải sinh output dài, nên áp lực nằm nhiều ở giai đoạn decode.
Các câu hỏi chính của bài test
- Nếu chỉ demo hoặc PoC với ít người dùng, engine nào cho cảm giác phản hồi nhanh nhất?
- Nếu triển khai chatbot cho nhiều người dùng đồng thời, engine nào scale-out tốt hơn?
- Nếu workload là RAG với context dài, cấu hình nào xử lý prefill hiệu quả hơn?
- Nếu workload là Coder sinh output dài, engine nào giữ tốc độ decode ổn định hơn?
- Nếu doanh nghiệp chưa rõ workload tương lai, cấu hình nào là baseline ít rủi ro hơn?
Bảng cấu hình benchmark
| Nhóm cấu hình | Kiểu triển khai | Vai trò | Mục tiêu kiểm tra |
|---|---|---|---|
| vLLM 1N | Single-node | Baseline vLLM | Đo hiệu năng vLLM ở tải thấp, ít overhead |
| SGLang 1N | Single-node | Baseline SGLang | Đo hiệu năng SGLang single-node |
| vLLM Ray 2N | Ray cluster | Scale-out vLLM | Kiểm tra khả năng mở rộng vLLM qua Ray |
| vLLM K8s 2N | Kubernetes | vLLM trên K8s | Đánh giá hiệu quả khi triển khai vLLM trong Kubernetes |
| SGLang 2N 1P1D | K8s Prefill/Decode Disaggregation | 1 Prefill, 1 Decode | Kiểm tra hiệu quả tách Prefill và Decode ở quy mô nhỏ |
| SGLang 4N 1P3D | K8s Prefill/Decode Disaggregation | 1 Prefill, 3 Decode | Tối ưu cho Chatbot tải cao, decode-heavy |
| SGLang 4N 2P2D | K8s Prefill/Decode Disaggregation | 2 Prefill, 2 Decode | Cấu hình cân bằng cho Chatbot + RAG |
Bảng kịch bản test tổng quan
| Mã kịch bản | Workload | Input/Output đặc trưng | Concurrency | Mục đích |
|---|---|---|---|---|
| c1 | Chatbot tải thấp | Prompt ngắn, output vừa | 1 user | Đo cảm giác phản hồi ban đầu |
| c64 | Chatbot tải cao | Prompt ngắn, nhiều user đồng thời | 64 users | Đo năng lực phục vụ nhiều user |
| OSL256 – OSL2048 | Coder output dài | Sinh output từ 256 đến 2048 tokens | Theo bài test coder | Đo độ ổn định khi sinh output dài |
| RAG 16K | RAG context dài | Input dài khoảng 16K tokens | Theo bài test RAG | Đo năng lực đọc context dài trước khi trả lời |
Tiếp tục đọc

