Groq LPU là gì? Giải thích kiến trúc bộ xử lý AI tốc độ cao
Groq LPU là gì? Giải thích kiến trúc bộ xử lý AI tốc độ cao
Groq giới thiệu Language Processing Unit (LPU) – kiến trúc chip mới được thiết kế riêng cho suy luận AI, mang lại tốc độ nhanh hơn và hiệu quả năng lượng vượt trội so với GPU truyền thống.
Tổng quan
Groq chuyên phát triển các giải pháp suy luận AI tốc độ cao. Công nghệ suy luận AI Groq® LPU™ mang lại tốc độ tính toán, chất lượng và khả năng chi trả vượt trội ở quy mô lớn. Cơ sở hạ tầng suy luận AI của Groq, cụ thể là GroqCloud™, được vận hành bởi Language Processing Unit (LPU) – một loại bộ xử lý hoàn toàn mới. Groq đã thiết kế và chế tạo LPU từ nền tảng gốc để đáp ứng các nhu cầu độc đáo của AI. LPU có thể chạy các Mô hình Ngôn ngữ Lớn (LLM) và nhiều mô hình tiên tiến khác với tốc độ nhanh hơn đáng kể, đồng thời hiệu quả hơn về mặt năng lượng lên đến 10 lần so với GPU ở cấp độ kiến trúc. Dưới đây là bốn nguyên tắc thiết kế cốt lõi của Groq LPU và lý do tại sao kiến trúc này mang lại hiệu suất vượt trội.

Bối cảnh phát triển
Trong nhiều thập kỷ, phần mềm máy tính đã hưởng lợi từ Định luật Moore – lời tiên tri năm 1965 của Gordon Moore về việc sức mạnh xử lý của chip sẽ tăng gấp đôi sau mỗi hai năm trong khi chi phí vẫn được duy trì ổn định. Định luật này đã đúng trong nhiều thập kỷ, được hỗ trợ bởi việc sử dụng ngày càng rộng rãi các bộ xử lý đa lõi (CPU và GPU). Mỗi bước tiến của phần cứng này đều đưa thêm nhiều phức tạp vào hệ thống. Ví dụ, CPU và GPU đa lõi rất mạnh mẽ và có thể xử lý nhiều loại ứng dụng khác nhau, nhưng chúng yêu cầu các thành phần phụ trợ trên silicon như bộ nhớ đệm (cache), bộ đệm (buffer) và bộ tiền tải (prefetcher) để tối ưu hóa việc thực thi. Sự phức tạp này tạo ra những bất thường trong quá trình thực thi chương trình tại thời điểm chạy. Điều này có thể được quản lý bởi các kernel phần mềm, nhưng bản thân chúng lại rất phức tạp.

Với sự chuyển dịch sang suy luận AI và sự xuất hiện của LLM cùng các tác vụ AI tương tự, Groq đã tận dụng cơ hội để rethink kiến trúc phần mềm và phần cứng. LLM rất mạnh mẽ, nhưng khi chạy ở chế độ suy luận, chúng dựa vào một tập hợp hạn chế các phép toán đại số tuyến tính, chủ yếu là nhân ma trận. Tính toán suy luận AI về cơ bản là chạy một lượng lớn các phép toán đại số tuyến tính trên dữ liệu quy mô lớn. Trong khi phần cứng GPU có thể lưu trữ các phép toán này, nó không được thiết kế cho mục đích đó. GPU luôn bị giới hạn về khả năng tăng tốc độ và hiệu quả suy luận do kiến trúc kế thừa được xây dựng cho các phép toán song song độc lập như xử lý đồ họa. Vì vậy, Groq đã tạo ra LPU. Bốn nguyên tắc thiết kế cốt lõi của nó mang lại lợi thế hiệu suất ngay hôm nay và trong tương lai, bao gồm: Kiến trúc dây chuyền lắp ráp có thể lập trình và Tính toán cùng mạng xác định.
Nguyên tắc thiết kế 1: Ưu tiên phần mềm
Kiến trúc Groq LPU bắt đầu với nguyên tắc ưu tiên phần mềm. Mục tiêu là giúp nhà phát triển phần mềm dễ dàng tối đa hóa việc sử dụng phần cứng và đặt càng nhiều quyền kiểm soát càng tốt vào tay nhà phát triển. GPU rất linh hoạt và mạnh mẽ; chúng có thể xử lý nhiều tác vụ tính toán khác nhau. Tuy nhiên, chúng cũng phức tạp, gây thêm gánh nặng cho phần mềm. Phần mềm phải tính đến sự biến đổi trong cách một tác vụ được thực thi, bên trong và giữa nhiều chip, khiến việc lập lịch thực thi tại thời điểm chạy và tối đa hóa việc sử dụng phần cứng trở nên khó khăn hơn. Để tối đa hóa việc sử dụng phần cứng trên GPU, mọi mô hình AI mới đều yêu cầu mã hóa các kernel cụ thể cho mô hình. Đây là lý do nguyên tắc ưu tiên phần mềm của chúng tôi rất quan trọng – với GPU, phần mềm luôn là thứ yếu so với phần cứng.

Groq LPU được thiết kế ngay từ đầu cho các phép tính đại số tuyến tính – yêu cầu chính cho suy luận AI. Bằng cách giới hạn trọng tâm vào tính toán đại số tuyến tính và đơn giản hóa mô hình tính toán đa chip, Groq đã tiếp cận suy luận AI và thiết kế chip theo một hướng khác. LPU sử dụng kiến trúc dây chuyền lắp ráp có thể lập trình, cho phép công nghệ suy luận AI sử dụng trình biên dịch chung, độc lập với mô hình và tuân thủ nguyên tắc ưu tiên phần mềm. Phần mềm luôn là chính, kiểm soát hoàn toàn mọi bước của quá trình suy luận. Ưu tiên phần mềm không chỉ là nguyên tắc thiết kế mà còn là cách Groq chế tạo bộ xử lý GroqChip™ thế hệ đầu tiên. Chúng tôi không chạm vào thiết kế chip cho đến khi kiến trúc của trình biên dịch được thiết kế xong. Trình biên dịch chấp nhận các tác vụ từ nhiều khung làm việc khác nhau, chạy chúng qua nhiều giai đoạn. Khi trình biên dịch ánh xạ và lập lịch cho chương trình chạy trên một hoặc nhiều LPU, nó sẽ tối ưu hóa hiệu suất và mức độ sử dụng. Kết quả là một chương trình bao gồm tất cả thông tin di chuyển dữ liệu trong suốt quá trình thực thi.
Nguyên tắc thiết kế 2: Kiến trúc dây chuyền lắp ráp có thể lập trình
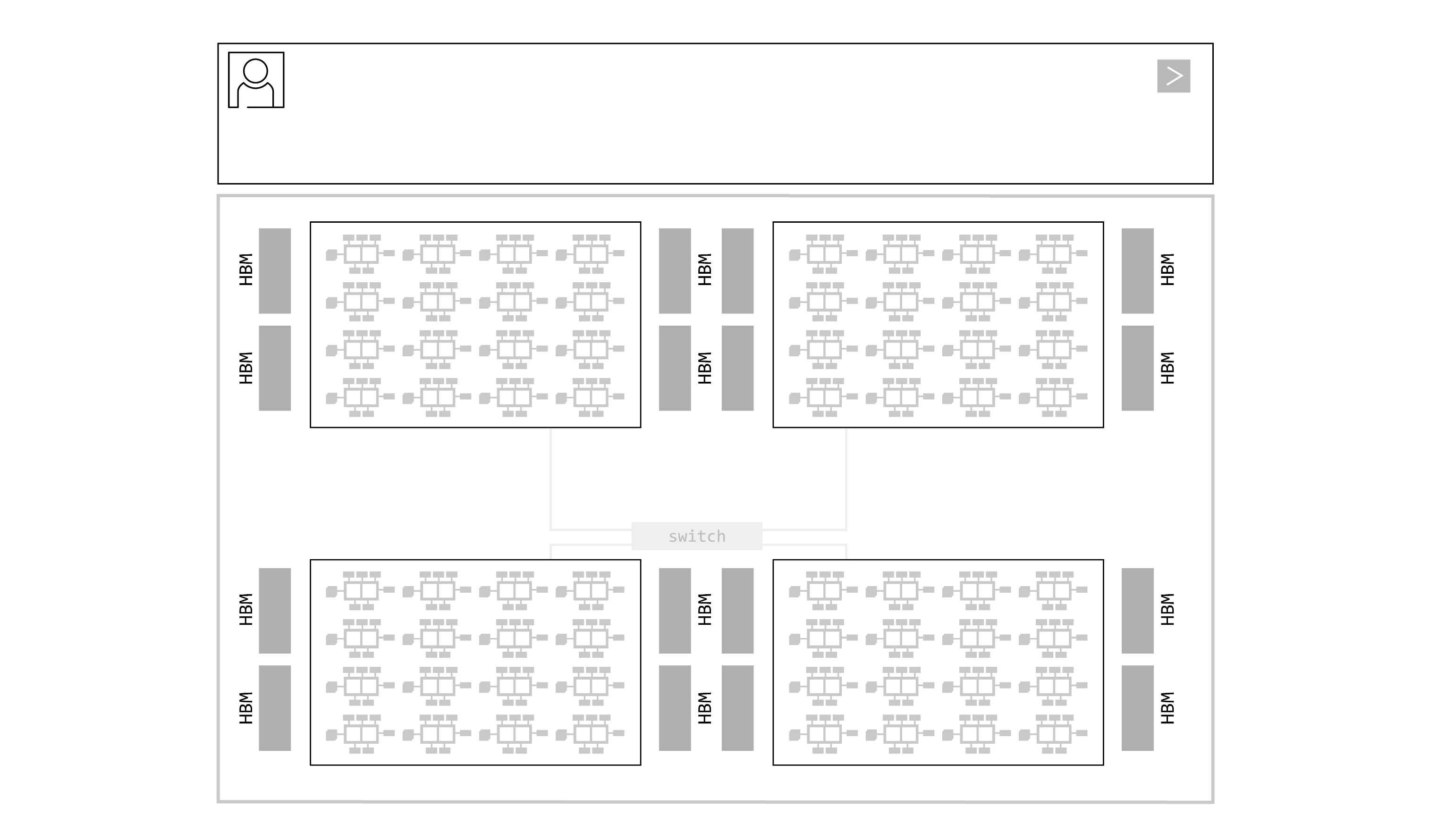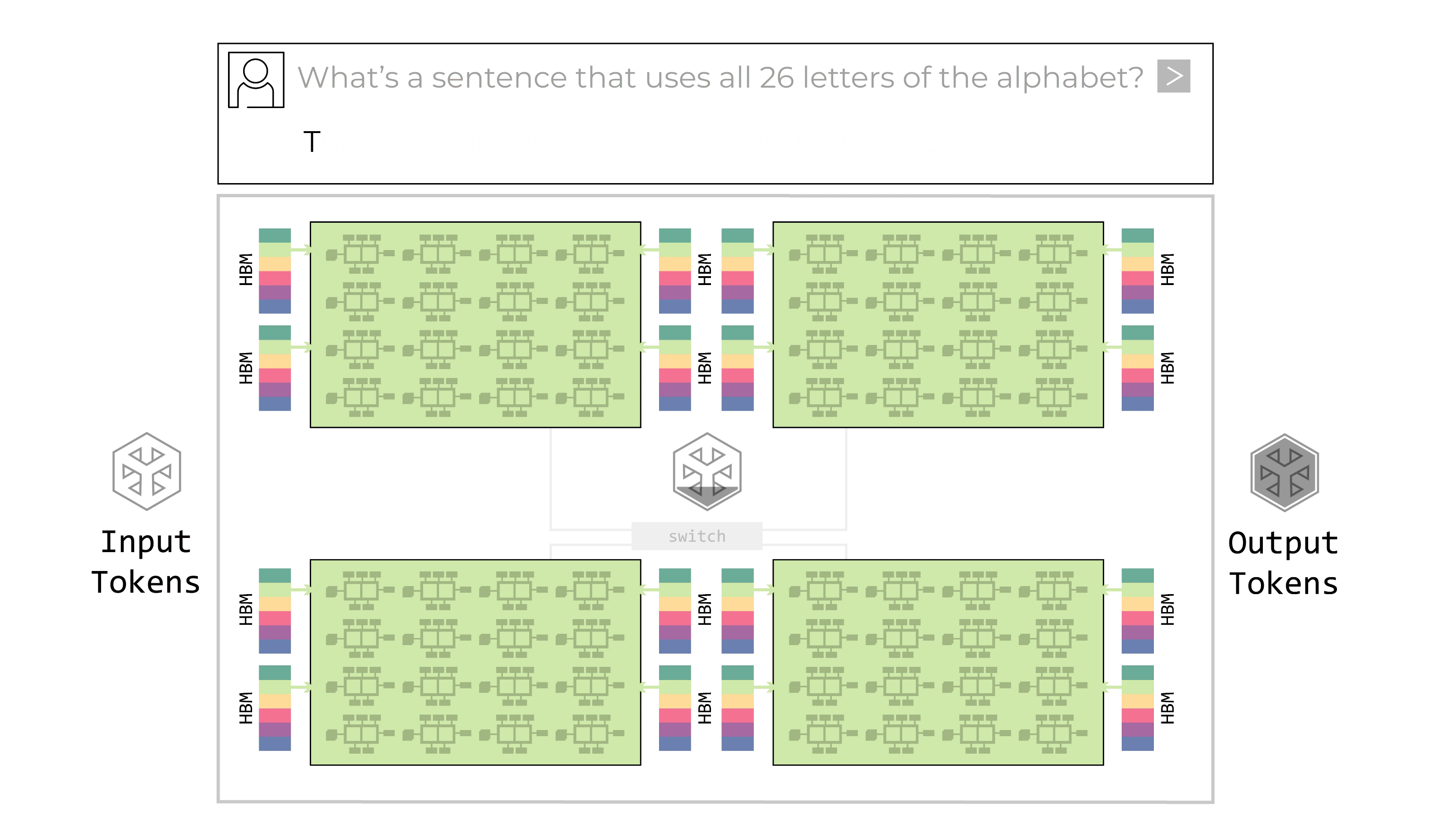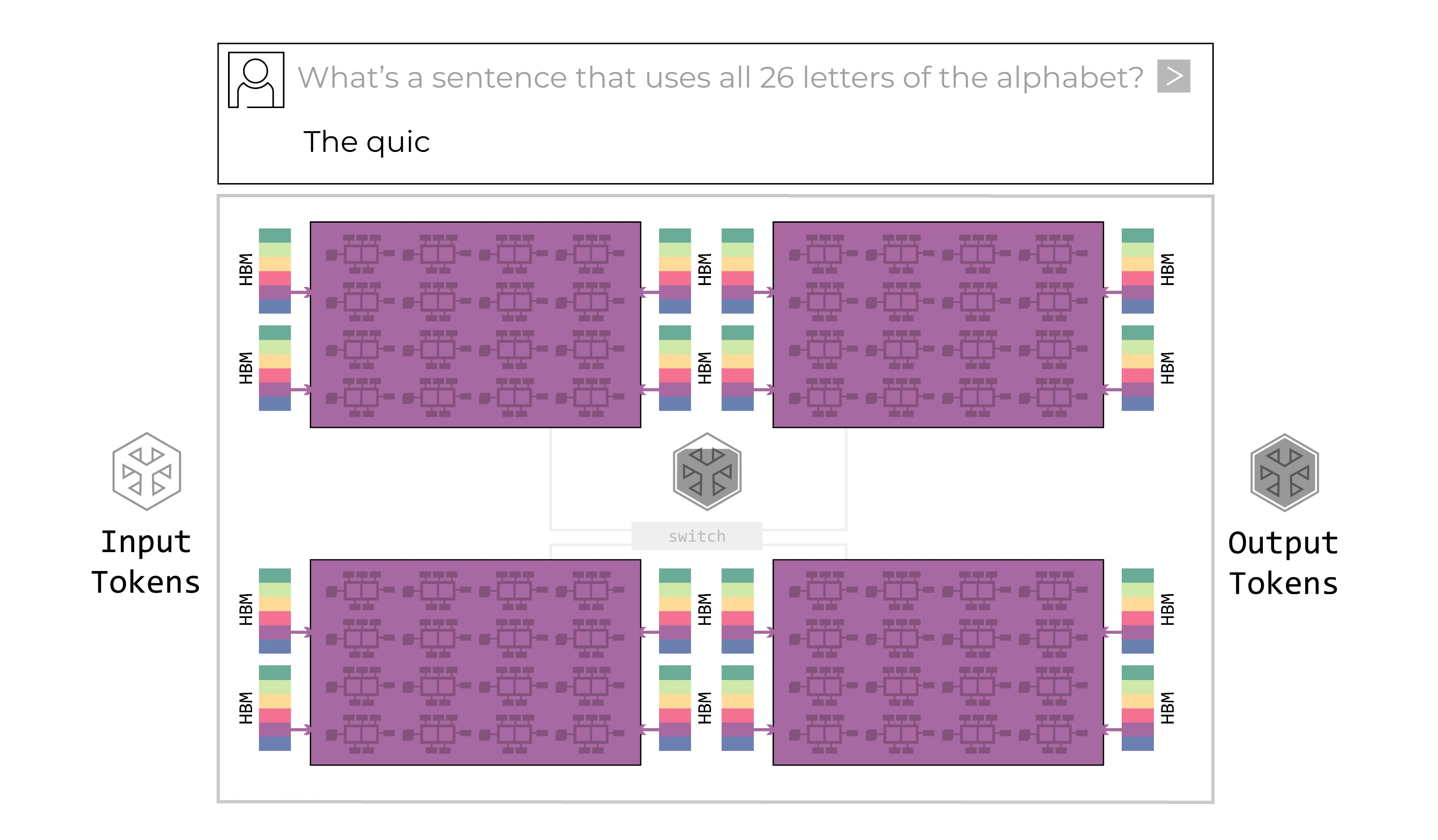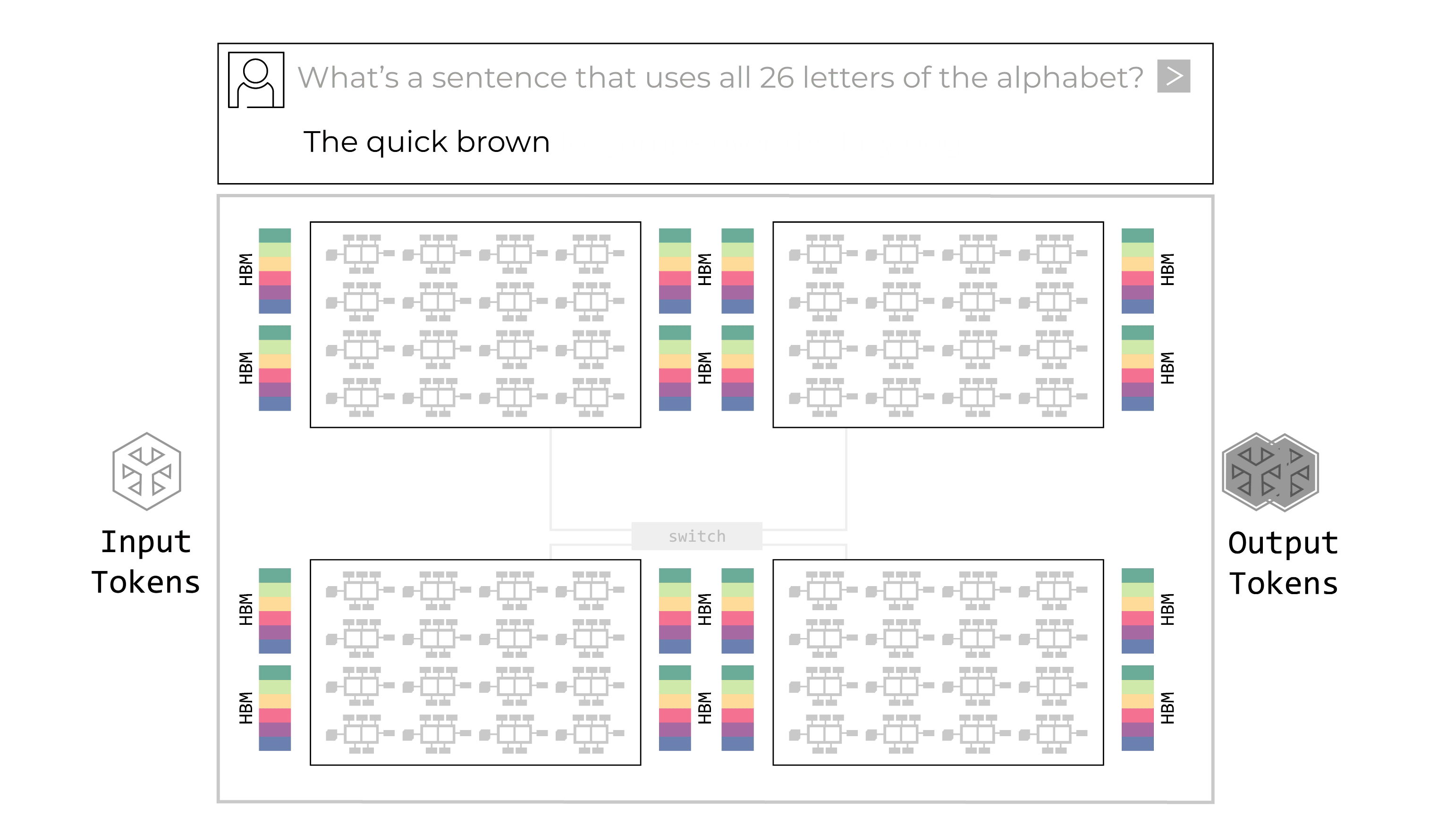
Tính năng xác định chính của Groq LPU là kiến trúc dây chuyền lắp ráp có thể lập trình. LPU có các “dây chuyền vận chuyển” dữ liệu di chuyển hướng dẫn và dữ liệu giữa các đơn vị chức năng SIMD (một hướng dẫn/nhiều dữ liệu) của chip. Tại mỗi bước của quy trình lắp ráp, đơn vị chức năng nhận hướng dẫn thông qua dây chuyền vận chuyển. Các hướng dẫn cho biết đơn vị chức năng nên lấy dữ liệu đầu vào từ đâu (dây chuyền nào), nên thực hiện chức năng gì với dữ liệu đó và nên đặt dữ liệu đầu ra ở đâu. Toàn bộ quy trình này được kiểm soát bởi phần mềm; không cần đồng bộ hóa trong phần cứng.
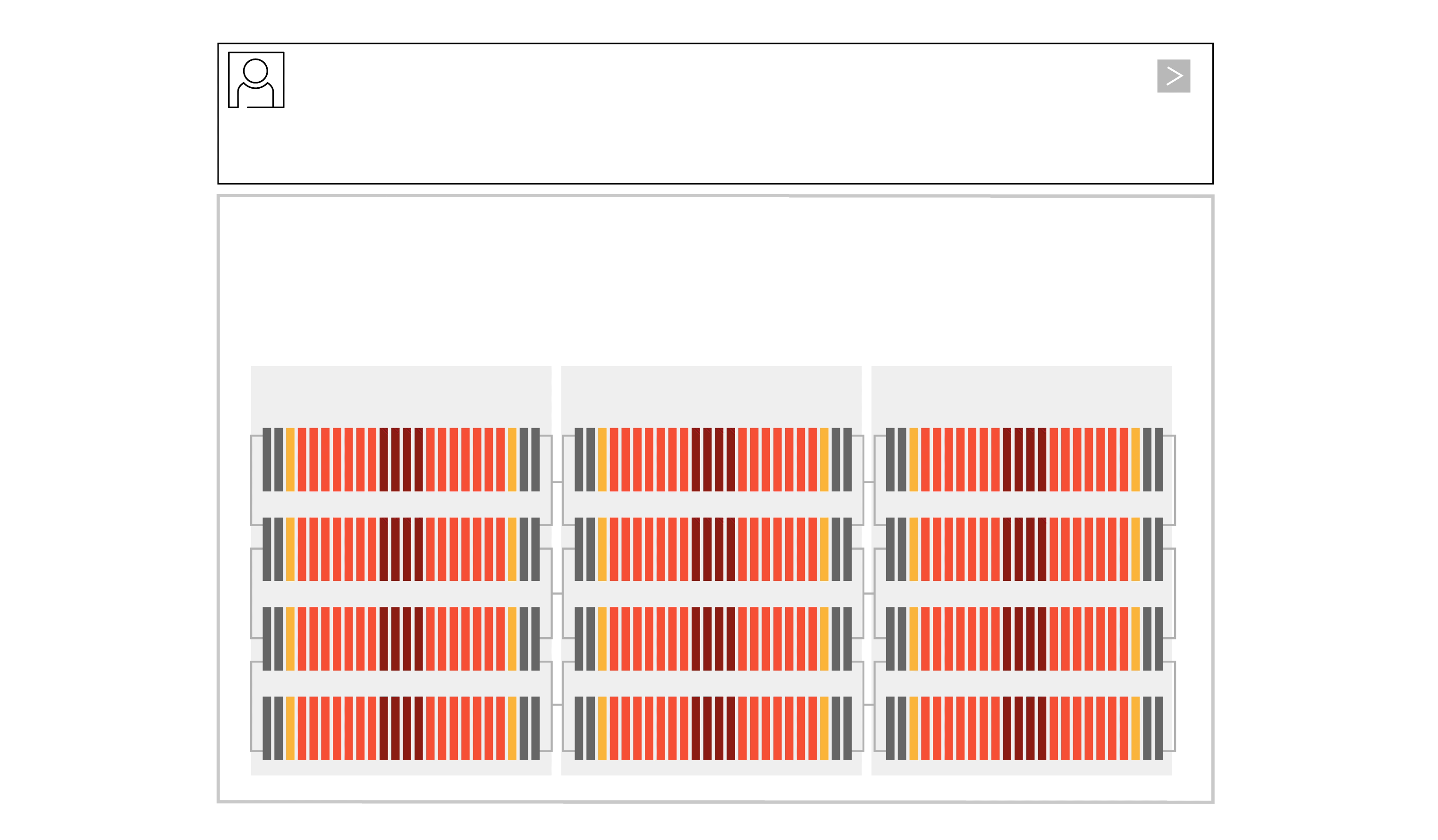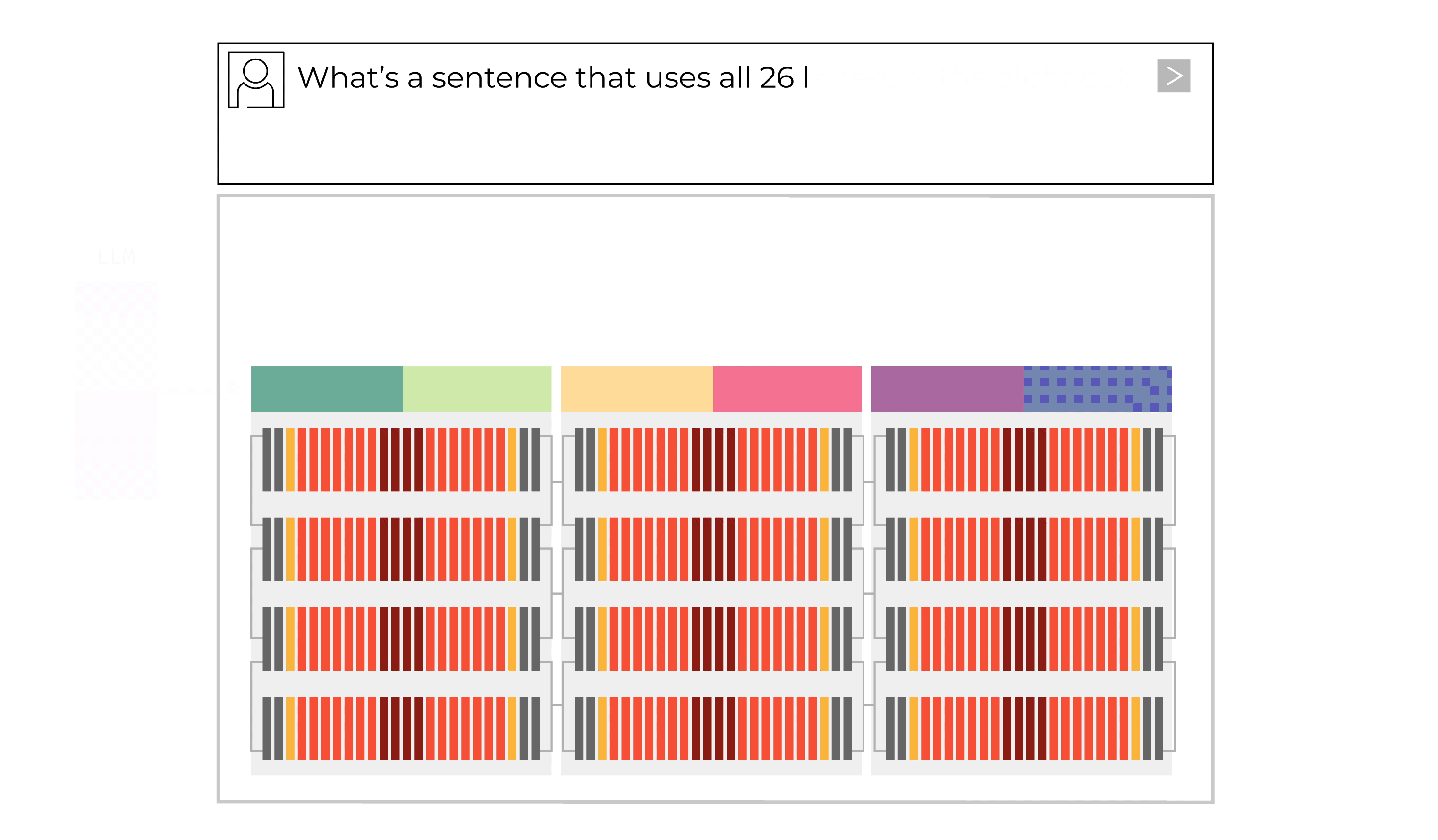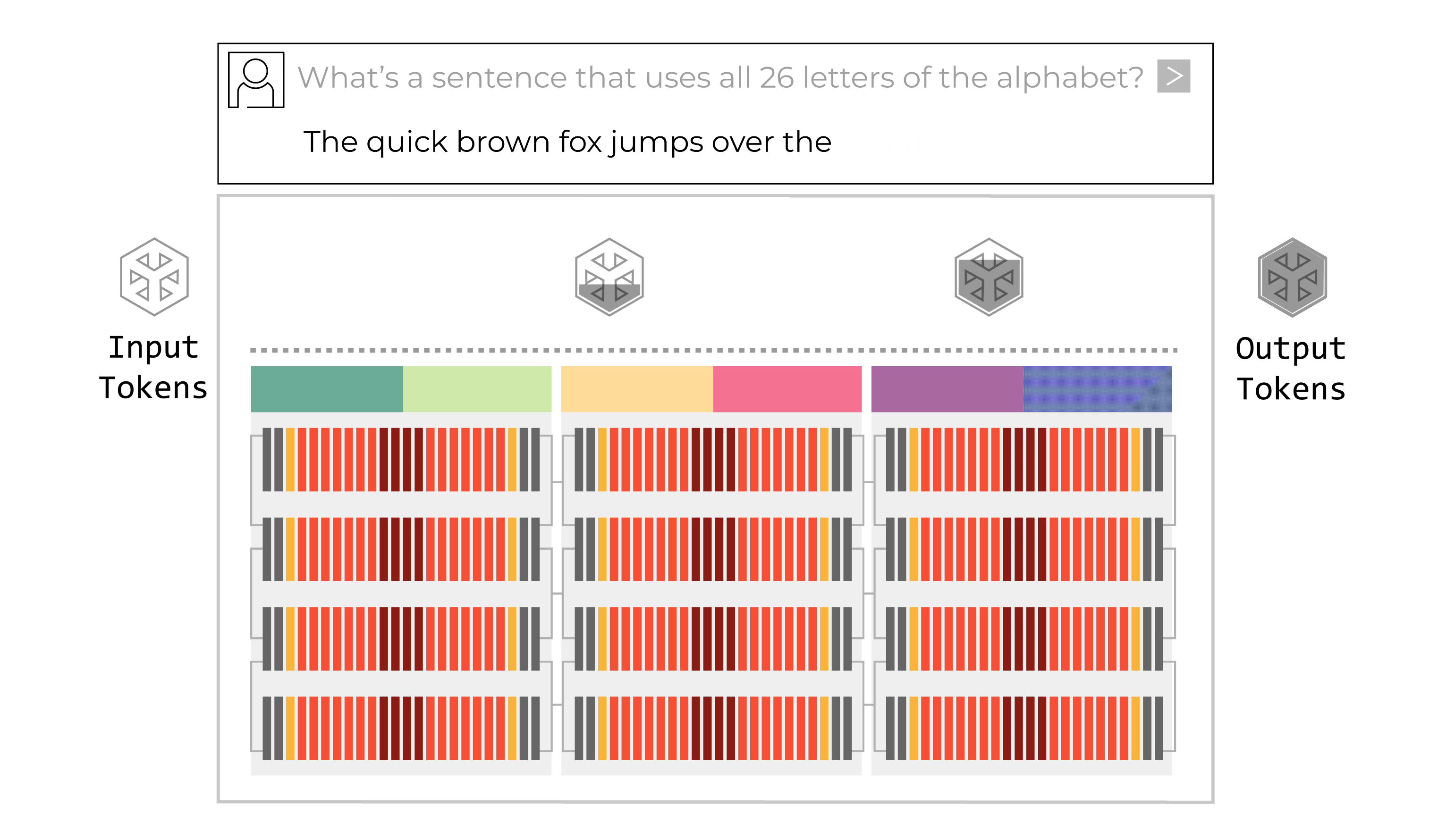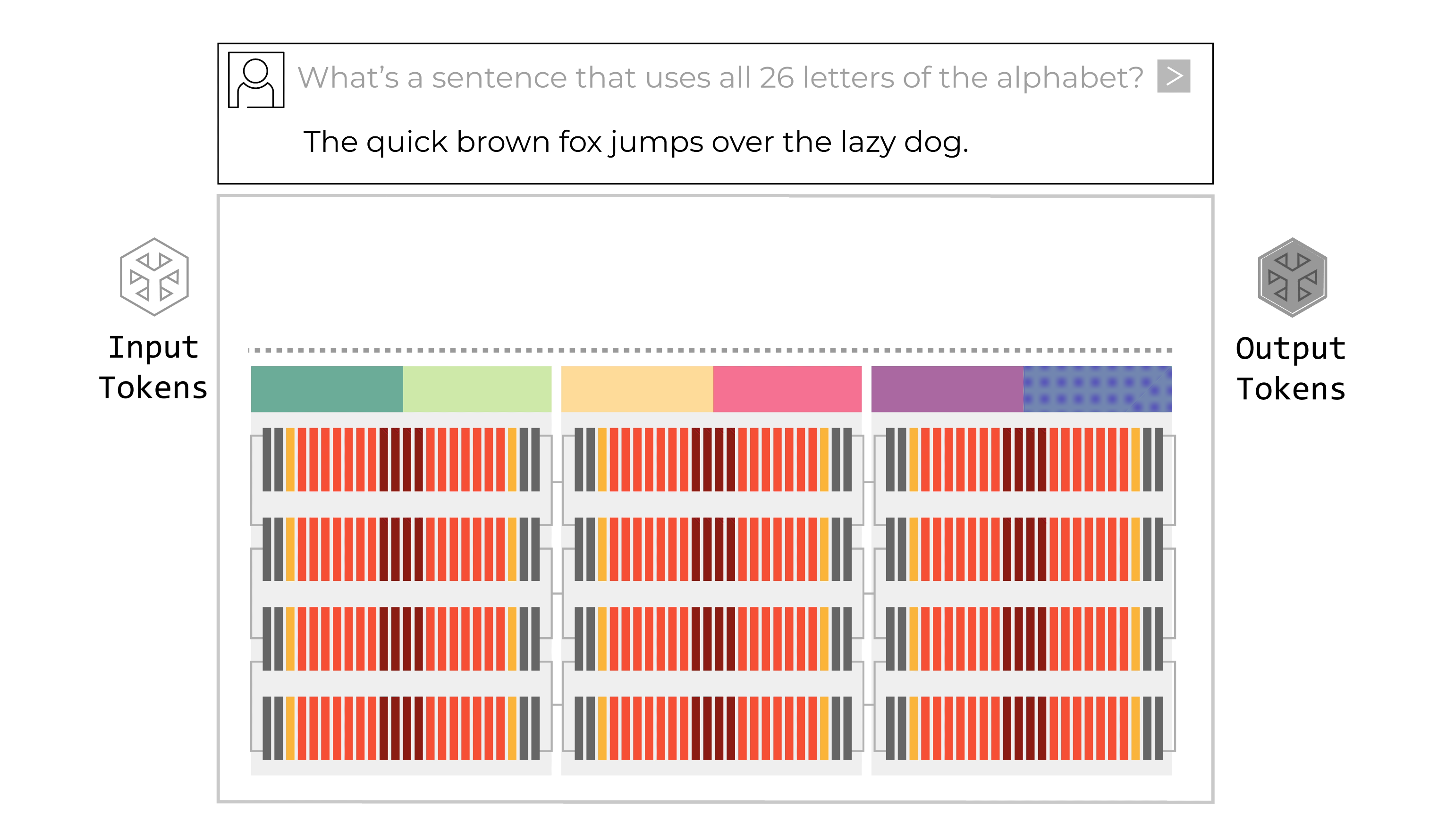
Kiến trúc luồng có thể lập trình của LPU hỗ trợ quy trình dây chuyền lắp ráp bên trong chip cũng như giữa các chip. Băng thông giữa các chip rất dồi dào, cho phép dây chuyền vận chuyển dữ liệu chảy giữa các chip dễ dàng như trong một chip. Không cần bộ định tuyến hoặc bộ điều khiển cho kết nối giữa các chip, ngay cả ở công suất tối đa. Quy trình dây chuyền lắp ráp bên trong và giữa các chip loại bỏ các nút thắt cổ chai. Không có sự chờ đợi tài nguyên tính toán hoặc bộ nhớ để hoàn thành tác vụ. Không cần bộ điều khiển bổ sung trên chip vì không có nút thắt cổ chai để quản lý. Dây chuyền lắp ráp di chuyển mượt mà và hiệu quả, hoàn toàn đồng bộ. Đây là một cải tiến lớn so với cách hoạt động của GPU. GPU hoạt động theo mô hình “trung tâm và spoke” đa lõi, nơi phương pháp phân trang dữ liệu kém hiệu quả yêu cầu đáng kể chi phí phụ trợ để chuyển dữ liệu qua lại giữa các đơn vị tính toán và bộ nhớ bên trong và giữa các chip. GPU cũng sử dụng nhiều cấp độ bộ chuyển mạch và chip mạng bên ngoài, cả bên trong và giữa các tủ rack, để giao tiếp với nhau, làm trầm trọng thêm độ phức tạp trong lập lịch phần mềm. Kết quả là một cách tiếp cận đa lõi khó lập trình. Kiến trúc dây chuyền lắp ráp có thể lập trình của Groq LPU nhanh hơn và hiệu quả hơn nhiều so với cách tiếp cận “trung tâm và spoke” của GPU.
Nguyên tắc thiết kế 3: Tính xác định trong tính toán và mạng
Để dây chuyền lắp ráp hoạt động hiệu quả, cần có độ chắc chắn cao về chính xác thời gian mỗi bước sẽ mất. Nếu có quá nhiều biến đổi về thời gian thực hiện một tác vụ cụ thể, sự biến đổi đó sẽ lan tỏa trên toàn bộ dây chuyền lắp ráp. Một dây chuyền lắp ráp hiệu quả đòi hỏi tính xác định cực kỳ chính xác. Kiến trúc LPU mang tính xác định, nghĩa là mọi bước thực thi đều hoàn toàn có thể dự đoán được đến chu kỳ thực thi nhỏ nhất (còn được gọi là chu kỳ xung nhịp). Phần cứng được kiểm soát bởi phần mềm biết chính xác khi nào và ở đâu một thao tác sẽ xảy ra và mất bao lâu. Groq LPU đạt được mức độ xác định cao bằng cách loại bỏ sự cạnh tranh cho các tài nguyên quan trọng, cụ thể là băng thông dữ liệu và tính toán. Có đủ dung lượng để định tuyến dữ liệu xung quanh chip (các dây chuyền vận chuyển) và đủ sức mạnh tính toán trong các đơn vị chức năng của chip. Không có vấn đề về các tác vụ khác nhau sử dụng cùng một tài nguyên, do đó không có độ trễ thực thi do nút thắt cổ chai tài nguyên. Điều tương tự cũng đúng cho việc định tuyến dữ liệu giữa các chip. Các dây chuyền vận chuyển dữ liệu LPU cũng hoạt động giữa các chip, vì vậy kết nối các chip sẽ tạo ra một dây chuyền lắp ráp có thể lập trình lớn hơn. Dòng dữ liệu được lập lịch tĩnh bởi phần mềm trong quá trình biên dịch và thực thi giống hệt nhau mỗi khi chương trình chạy.
Nguyên tắc thiết kế 4: Bộ nhớ trên chip
LPU bao gồm cả bộ nhớ và bộ xử lý trên cùng một chip, cải thiện đáng kể tốc độ lưu trữ và truy xuất dữ liệu đồng thời loại bỏ biến đổi thời gian. Trong khi tính xác định đảm bảo dây chuyền lắp ráp chạy hiệu quả và loại bỏ biến đổi của mỗi giai đoạn tính toán, bộ nhớ trên chip cho phép nó chạy nhanh hơn nhiều. GPU sử dụng các chip bộ nhớ băng thông cao riêng biệt, đưa vào sự phức tạp – nhiều lớp bộ nhớ đệm, bộ chuyển mạch và bộ định tuyến để di chuyển dữ liệu qua lại – đồng thời tiêu thụ đáng kể năng lượng. Việc có bộ nhớ trên cùng một chip cải thiện hiệu quả và tốc độ của mỗi hành động I/O và loại bỏ sự phức tạp và không chắc chắn. Bộ nhớ SRAM trên chip của Groq có băng thông bộ nhớ lên tới hơn 80 terabyte/giây, trong khi bộ nhớ HBM ngoài chip của GPU chỉ đạt khoảng tám terabyte/giây. Sự khác biệt này đã mang lại cho LPU lợi thế tốc độ lên đến 10 lần, cộng thêm lợi thế từ việc không phải quay lại chip bộ nhớ riêng biệt để truy xuất dữ liệu.
Kết luận
Groq LPU mang lại tốc độ, chất lượng và khả năng chi trả vượt trội ở quy mô lớn. Nhờ các nguyên tắc thiết kế vốn có, lợi thế hiệu suất của LPU là bền vững. GPU sẽ tiếp tục cải thiện tốc độ và chi phí, nhưng Groq cũng sẽ phát triển nhanh hơn nhiều. Bộ chip hiện tại của chúng tôi được xây dựng trên quy trình 14 nanomet. Khi chuyển sang quy trình 4 nanomet, lợi thế hiệu suất của kiến trúc LPU sẽ chỉ tăng lên. Đây là những “nguyên lý cơ bản” tại Groq hướng dẫn phát triển sản phẩm LPU. Chúng đảm bảo chúng tôi sẽ duy trì lợi thế hiệu suất đáng kể ngay cả khi các nhà sản xuất GPU cố gắng thu hẹp khoảng cách.
Groq được thành lập năm 2016 với một mục tiêu duy nhất: suy luận AI. Tích hợp liền mạch Groq bắt đầu với chỉ vài dòng mã.
Overview
Groq specializes in high-speed AI inference. Groq® LPU™ AI inference technology delivers exceptional compute speed, quality, and affordability at scale. Groq’s AI inference infrastructure, specifically GroqCloud™, is powered by the Language Processing Unit (LPU), a new processor category. Groq designed and built the LPU from the ground up to meet AI’s unique needs. LPUs run Large Language Models (LLMs) and other leading models at substantially faster speeds and, architecturally, up to 10x more efficiently from an energy perspective compared to GPUs. Below are the four core design principles of the Groq LPU and why its architecture delivers exceptional performance.
Background
For decades, computer software benefited from Moore’s Law, Gordon Moore’s 1965 prophecy that chip processing power would double roughly every two years while costs remained steady. The law held for decades, aided by the growing use of multi-core processors (CPUs and GPUs). Each hardware progression introduced more system complexity. Multi-core CPUs and GPUs are powerful but require silicon ancillary components like caches, buffers, and prefetchers to optimize execution. This complexity creates runtime inconsistencies. While software kernels can manage this, they add their own complexity. With the shift toward AI inference and the emergence of LLMs, Groq rethought software and hardware architecture. LLMs rely on a limited set of linear algebra operations, primarily matrix multiplication. While GPU hardware can host these operations, it wasn’t designed for them. GPUs are inherently limited in inference speed and efficiency due to their legacy architecture built for independent parallel operations like graphics processing. Thus, Groq built the LPU.
Design Principle 1: Software-First
The Groq LPU architecture began with a software-first principle. The goal was to simplify maximizing hardware utilization for developers and place control in their hands. GPUs are versatile but complex, burdening software with scheduling variability across chips. To maximize GPU utilization, every new AI model requires model-specific kernel coding. With the LPU, software is primary, controlling every inference step. The LPU uses a programmable assembly line architecture, enabling a generic, model-independent compiler. Groq built its first-generation GroqChip™ processor only after designing the compiler’s architecture. The compiler maps and schedules workloads across one or multiple LPUs, optimizing performance and embedding all data movement information into the final program.
Design Principle 2: Programmable Assembly Line Architecture
The LPU’s defining feature is its programmable assembly line architecture. Data “conveyor belts” move instructions and data between the chip’s SIMD function units. Each unit receives instructions via the belt, determining data sources, operations, and output locations. This process is entirely software-controlled, requiring no hardware synchronization. The architecture supports chip-to-chip data flow with ample bandwidth, eliminating the need for routers or controllers. This smooth, synchronized process contrasts sharply with the GPU’s inefficient “hub and spoke” multi-core model, which relies on complex data paging, external switches, and networking chips that exacerbate scheduling complexity.
Design Principle 3: Deterministic Compute and Networking
Efficient assembly lines require precise predictability. The LPU architecture is deterministic, meaning every execution step is fully predictable down to the clock cycle. The software-controlled hardware knows exactly when, where, and how long an operation will take. Groq achieves this by eliminating contention for critical resources like data bandwidth and compute. Ample routing capacity and functional unit compute prevent resource bottlenecks. Data flow is statically scheduled by the compiler during compilation and executes identically every time the program runs.
Design Principle 4: On-Chip Memory
LPUs integrate both memory and compute on the same chip, drastically improving data storage/retrieval speed and eliminating timing variation. While determinism ensures efficiency, on-chip memory enables much faster execution. GPUs use separate high-bandwidth memory chips, introducing cache layers, switches, and routers that consume significant energy. Groq’s on-chip SRAM offers memory bandwidth exceeding 80 terabytes/second, compared to GPU off-chip HBM at roughly 8 terabytes/second. This alone provides LPUs up to a 10x speed advantage, further boosted by eliminating往返 trips to separate memory chips.
Conclusion
The Groq LPU delivers exceptional speed, quality, and affordability at scale. Its inherent design principles ensure durable performance superiority. While GPUs will continue to improve, Groq advances at a much faster pace. The current chipset uses a 14-nanometer process, and the shift to 4 nanometers will only amplify LPU advantages. These “first principles” guide LPU development, ensuring sustained performance leadership even as GPU manufacturers attempt to close the gap. Groq was established in 2016 with one focus: inference. Seamlessly integrate Groq starting with just a few lines of code.

