MinIO bổ sung bộ nhớ đệm MemKV quy mô petabyte cho suy luận GPU của Nvidia
MinIO bổ sung bộ nhớ đệm MemKV quy mô petabyte cho suy luận GPU của Nvidia
MinIO vừa ra mắt MemKV, hệ thống bộ nhớ đệm quy mô petabyte được thiết kế riêng cho GPU Nvidia, hoạt động trên nền tảng AIStor nhằm giảm thiểu tình trạng mất ngữ cảnh và tối ưu hiệu suất suy luận AI ở quy mô lớn.
MinIO bổ sung bộ nhớ đệm MemKV quy mô petabyte cho suy luận GPU của Nvidia
MinIO vừa giới thiệu MemKV, hệ thống bộ nhớ đệm quy mô petabyte được tích hợp trực tiếp trên nền tảng lưu trữ đối tượng AIStor. Giải pháp này được thiết kế để tối ưu hóa đường truyền dữ liệu suy luận AI (inference data path) cho các cụm GPU của Nvidia, giải quyết bài toán mất ngữ cảnh và chi phí tái tính toán khi mở rộng quy mô.

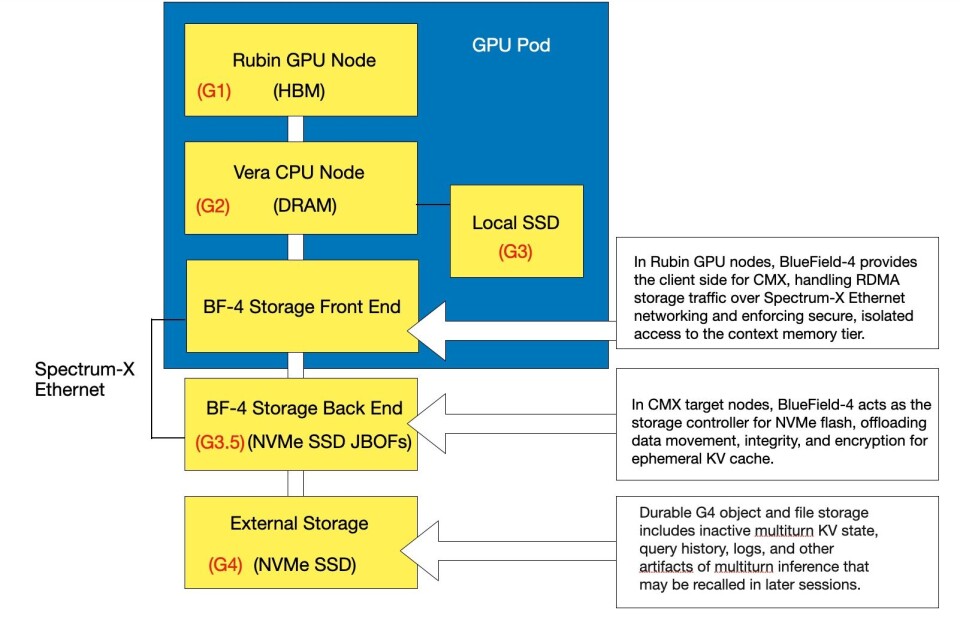
Trong các tác vụ suy luận AI, các cụm GPU yêu cầu bộ nhớ băng thông cao (HBM) để lưu trữ ngữ cảnh, token vector hóa và các cặp khóa-giá trị (KV) trung gian. Khi HBM đầy, dữ liệu sẽ được chuyển xuống bộ nhớ CPU DRAM, sau đó đến SSD NVMe thông qua phần mềm điều khiển chạy trên bộ xử lý DPU BlueField-4 (BF4) của Nvidia. Khi các tầng bộ nhớ này cũng đạt ngưỡng, hệ thống lưu trữ đối tượng hỗ trợ như AIStor của MinIO sẽ đảm nhận vai trò lưu trữ hỗ trợ. Kiến trúc STX của Nvidia định nghĩa cách vận hành hệ thống bộ nhớ đệm phân tầng này, và MemKV tuân thủ chuẩn STX để cung cấp ngữ cảnh chia sẻ, liên tục trên toàn cụm GPU ở quy mô mà MinIO nhận định các tầng bộ nhớ và lưu trữ hiện tại chưa đáp ứng được.

AB Periasamy, đồng sáng lập và đồng CEO của MinIO, chia sẻ: “Ngành công nghiệp đã che đậy vấn đề mất ngữ cảnh trong nhiều năm vì ở quy mô nhỏ, bạn có thể chịu chi phí tái tính toán và tiếp tục. Nhưng ở mật độ GPU mà các hyperscaler và neocloud đang hướng tới, điều đó không còn đúng nữa. Việc GPU phải tái tính toán ngữ cảnh đã tạo ra đang đốt cháy năng lượng mà không mang lại hiệu quả. Ở quy mô một nghìn GPU, đó không phải là sự kém hiệu quả nhỏ lẻ, mà là gánh nặng cấu trúc. Kinh tế năng suất ở quy mô này đòi hỏi một giải pháp được xây dựng riêng cho đường truyền dữ liệu suy luận. MemKV được thiết kế chính xác cho mục đích này.”
MinIO cho biết MemKV cho phép toàn bộ cụm GPU truy cập vào một pool ngữ cảnh chung với độ trễ microsecond, đồng bộ với tốc độ suy luận, thay vì phải chờ đợi độ trễ millisecond từ lưu trữ bên ngoài. Khi HBM, CPU DRAM và bộ nhớ đệm SSD cục bộ đầy, các GPU đắt tiền buộc phải tái tính toán ngữ cảnh. Theo MinIO, MemKV đã cải thiện đáng kể thời gian tạo token đầu tiên (time-to-first-token) ở mức độ đồng thời sản xuất. Trong một triển khai 128 GPU với độ dài ngữ cảnh 128K token, giải pháp này giúp tăng hiệu suất sử dụng GPU từ 50% lên hơn 90%, mang lại khoản tiết kiệm chi phí tính toán ước tính 2 triệu USD mỗi năm.
MemKV được xây dựng riêng cho đường truyền dữ liệu suy luận, tương thích với kiến trúc STX của Nvidia và hỗ trợ phần mềm bộ nhớ đệm Dynamo và NIXL. Giải pháp cung cấp bộ nhớ ngữ cảnh chia sẻ quy mô petabyte với chi phí ngang hàng SSD, thay thế các hạn chế về chi phí và dung lượng của HBM/DRAM GPU bằng một tầng lưu trữ có thể mở rộng độc lập với cụm tính toán. Các đặc điểm nổi bật của MemKV bao gồm:
- Hỗ trợ native BlueField-4 STX: Chạy trực tiếp trong hạ tầng STX dưới dạng binary ARM64, được nhúng vào tầng lưu trữ thay vì triển khai trên máy chủ lưu trữ x86 riêng biệt kết nối qua mạng.
- Vận chuyển RDMA đầu cuối: Dữ liệu KV cache di chuyển từ bộ nhớ GPU sang NVMe qua RDMA, bỏ qua hoàn toàn các giao thức hệ thống tệp hoặc lưu trữ đối tượng.
- Block size gốc cho GPU: Hoạt động với các block 2-16 MB được tối ưu cho mô hình truy cập hướng thông lượng của GPU, thay vì các block 4 KB truyền thống.
- Hiệu suất mạng tốc độ dây: Được xây dựng cho mạng Ethernet Nvidia Spectrum-X và PCIe Gen6, đạt thông lượng gần tốc độ dây trên toàn bộ hạ tầng vật lý.
MemKV di chuyển dữ liệu trực tiếp từ SSD NVMe vào đường truyền dữ liệu AI thông qua vận chuyển RDMA đầu cuối, không có overhead HTTP, không có lớp dịch chuyển hệ thống tệp và không có máy chủ lưu trữ trung gian giữa GPU và ngữ cảnh của nó.

MinIO nhấn mạnh rằng “mỗi nhà cung cấp lưu trữ” công bố hỗ trợ “bộ nhớ ngữ cảnh” hiện đang thực hiện một trong hai hướng: mở rộng giải pháp NVMe cục bộ (G3) không thể chia sẻ trên cụm, hoặc thích ứng nền tảng lưu trữ chia sẻ mục đích chung (G4) vào đường truyền suy luận. Cả hai đều không được thiết kế cho tác vụ này, nhưng MemKV được xây dựng từ đầu để chiếm lĩnh phân khúc G3.5. Công ty chỉ ra rằng khi các nhà cung cấp lưu trữ legacy tuyên bố hỗ trợ G3.5, dữ liệu vẫn phải đi qua các nút giao thức, dịch vụ metadata và lớp dịch chuyển hệ thống tệp truyền thống. Những lớp này tồn tại để đảm bảo độ bền doanh nghiệp, tính nhất quán ACID và mã hóa sửa lỗi (erasure coding) – điều hoàn toàn phù hợp cho dữ liệu huấn luyện và trọng số mô hình, nhưng không tối ưu cho KV cache vốn mang tính tạm thời, có thể tái tính toán và cần di chuyển theo các block 2-16 MB tối ưu cho suy luận.
Hiện nay, GRAID (nhà cung cấp hardware RAID do GPU hỗ trợ) và WEKA cũng có giải pháp KV cache hỗ trợ STX. Một nhóm lớn các nhà cung cấp lưu trữ khác đã chính thức đăng ký hỗ trợ kiến trúc STX của Nvidia, bao gồm Cloudian, Dell, DDN, Everpure, Hammerspace, Hitachi Vantara, HPE, Lightbits/ScaleFlux, NetApp, Nutanix, Peak:AIO, Pliops và VAST Data.
Nguồn: blocksandfiles.com
MinIO Adds Petabyte-Scale MemKV Cache for Nvidia GPU Inference
MinIO has launched MemKV, a petabyte-scale caching system built on its AIStor object storage platform. Designed specifically for Nvidia GPU inference workloads, MemKV addresses the growing challenge of context loss and recomputation costs in large-scale AI deployments.
AI inference clusters require tightly coupled high-bandwidth memory (HBM) to store context, vectorized tokens, and intermediate key-value (KV) pairs. When HBM fills, data cascades down to CPU DRAM and NVMe SSDs via software running on Nvidia’s BlueField-4 (BF4) DPUs. Once these layers are saturated, backing object storage like MinIO’s AIStor takes over. Nvidia’s STX architecture defines this caching hierarchy, and MemKV is built to comply with it, enabling persistent, shared context across GPU clusters at a scale MinIO says existing tiers cannot match.
AB Periasamy, MinIO’s co-founder and co-CEO, noted that while small-scale deployments can absorb the power cost of recomputing context, hyperscaler and neocloud densities make this approach unsustainable. “Yield economics at this scale demand something purpose-built for the inference data path. MemKV was designed for exactly this,” he said.
MinIO reports that MemKV enables microsecond-latency access to a shared context pool, significantly improving time-to-first-token. In a 128-GPU test with a 128K-token context length, GPU utilization rose from 50% to over 90%, delivering an estimated $2 million in annual compute savings.
MemKV is engineered for the inference data path, supporting Nvidia’s STX architecture, Dynamo, and NIXL caching software. Its core features include native BF4 STX support as a single ARM64 binary, end-to-end RDMA transport that bypasses file system and object protocols, 2-16 MB GPU-optimized block sizes, and wire-speed fabric performance built for Nvidia Spectrum-X Ethernet and PCIe Gen6.
By moving data directly from NVMe SSDs to the AI data path via RDMA, MemKV eliminates HTTP overhead, file system translation, and intermediate storage servers.
MinIO distinguishes MemKV as a G3.5 solution, arguing that legacy vendors typically offer either local NVMe (G3) or adapted general-purpose shared storage (G4). Unlike traditional systems optimized for ACID consistency and erasure coding, MemKV is built for ephemeral, recomputable KV cache that moves in inference-optimized blocks.
Alongside GRAID and WEKA, a broad ecosystem of storage providers—including Cloudian, Dell, DDN, Everpure, Hammerspace, Hitachi Vantara, HPE, Lightbits/ScaleFlux, NetApp, Nutanix, Peak:AIO, Pliops, and VAST Data—has committed to supporting Nvidia’s STX architecture.
Source: blocksandfiles.com

